6 分钟了解 HTTP 发展史
次访问
HTTP/0.9
HTTP/0.9 是于 1991 年提出的,主要用于学术交流,需求很简单——用来在网络之间传递 HTML 超文本的内容,所以被称为超文本传输协议。整体来看,它的实现也很简单,采用了基于请求响应的模式,从客户端发出请求,服务器返回数据。
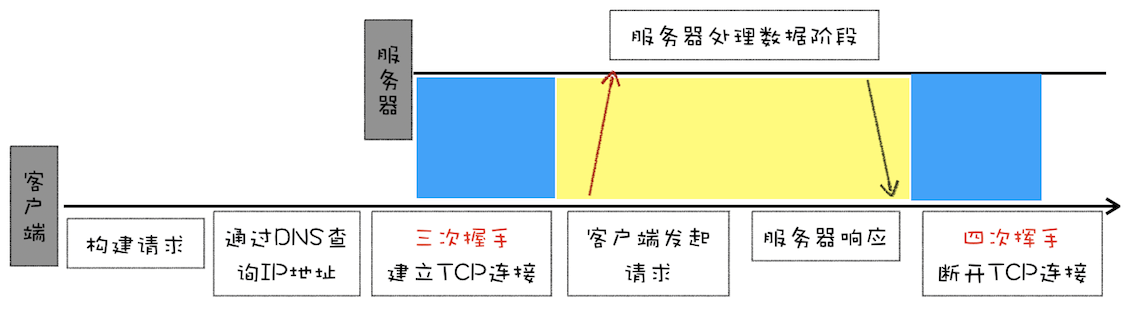
完整请求流程
- 因为 HTTP 都是基于 TCP 协议的,所以客户端先要根据 IP 地址、端口和服务器建立 TCP 连接,而建立连接的过程就是 TCP 协议三次握手的过程。
- 建立好连接之后,会发送一个 GET 请求行的信息,如 GET /index.html 用来获取 index.html。
- 服务器接收请求信息之后,读取对应的 HTML 文件,并将数据以 ASCII 字符流返回给客户端。
- HTML 文档传输完成后,断开连接。
特点
- 第一个是只有一个请求行,并没有 HTTP 请求头和请求体,因为只需要一个请求行就可以完整表达客户端的需求了。
- 第二个是服务器也没有返回头信息,这是因为服务器端并不需要告诉客户端太多信息,只需要返回数据就可以了。
- 第三个是返回的文件内容是以 ASCII 字符流来传输的,因为都是 HTML 格式的文件,所以使用 ASCII 字节码来传输是最合适的。
HTTP/1.0
HTTP/0.9 存在许多的问题,比如如下的这些:
- 只支持 HTML 类型文件,无法传输 JS、CSS、字体、图片和视频等类型的文件;
- 文件传输格式局限于 ASCII,无法输出其他类型编码的文件;
- 只有请求行,传输给服务器的信息太少;
- 只响应请求数据,不能传输额外的数据给浏览器。
所以它已经不能满足当时的需求了,于是乎 HTTP/1.0 来了,它带来了这些:
新增了请求头和请求体,能传输更多的信息给服务器,比如如下请求头字段:Accept 文件类型,Accept-Encoding 压缩格式,Accept-Charset 字符编码格式,Accept-Language 国际化语音:
1
2
3
4Accept: text/html
Accept-Encoding: gzip, deflate, br
Accept-Charset: ISO-8859-1,utf-8
Accept-Language: zh-CN,zh请求头新增 User-Agent 字段,用于服务器统计客户端信息:
1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36
新增了响应头,能够告诉浏览器更多的信息,比如 Content-Encoding 表示服务器返回文件的压缩类型,Content-Type 告诉浏览器服务器返回的是什么类型的文件以及使用了什么编码格式:
1
2Content-Encoding: gzip
Content-Type: text/html; charset=utf-8新增响应行状态码,用于告知浏览器当前请求的状态,比如 200 表示请求成功:
1
HTTP/1.1 200 OK
新增缓存机制,用来缓存已经下载过的资源,减轻了服务端压力。
在构建请求流程上来看,HTTP/1.0 区别于 HTTP/0.9 最大的区别就是在请求和响应的时候新增了不少字段用于在浏览器和服务器之间通信。
HTTP/1.1
HTTP/1.0 虽说已经能够传输不同类型的文件了,但是它还是有缺点的,比如每发出一次 HTTP 请求都需要经历如下阶段:
- 建立 TCP 连接;
- HTTP 请求;
- HTTP 响应;
- 断开 TCP 连接。
HTTP/1.0 发送多个同域名请求:
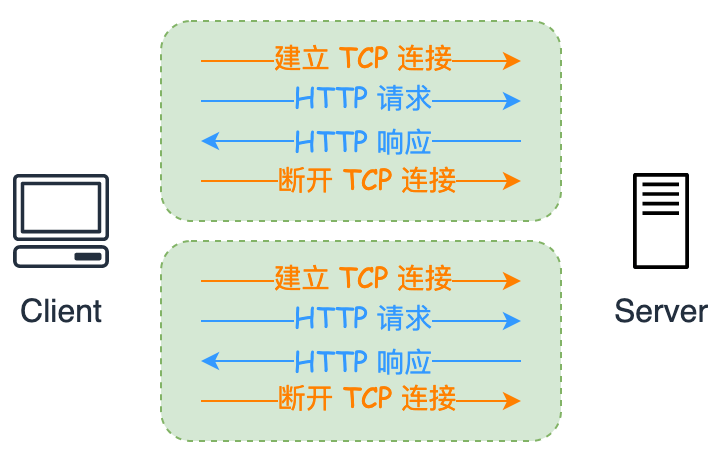
可以发现每次请求都需要重新建立 TCP 连接和断开连接的操作,这无疑增加了网络开销,同时也延迟了页面显示。
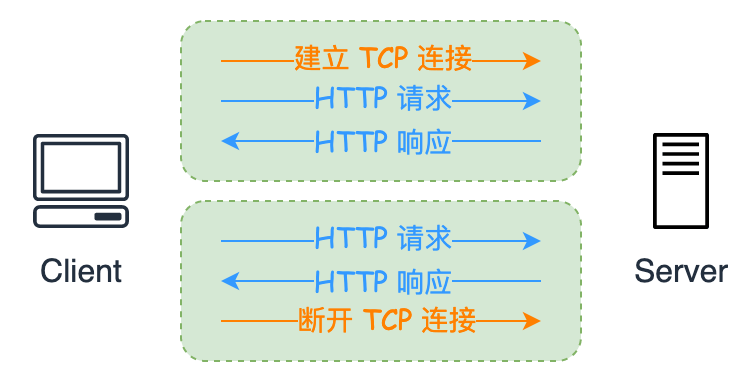
HTTP/1.1 在请求头中增加了 Connection 字段:用于提供 TCP 的持久连接**:
1 | Connection: keep-alive |
它默认是开启持久连接的,即对于同一个域名,浏览器默认支持 6 个 TCP 持久连接。
当启用持久连接后,多个同域名下的请求发送会是如下情况:
HTTP/1.1 中新增 Host 字段,用于支持虚拟主机
1 | Host: bubuzou.com |
虚拟主机:一台物理机器上绑定多个虚拟主机,每个虚拟主机有单独的域名,这些域名都公用一个 IP 地址。
HTTP/1.1 通过引入 Chunk transfer 机制来支持动态内容:服务器会将数据分割成若干个任意大小的数据块,每个数据块发送时会附上上个数据块的长度,最后使用一个零长度的块作为发送数据完成的标志。
HTTP/1.1 还引入了客户端 Cookie 机制和安全机制
HTTP/2
我们知道 HTTP/1.1 为网络效率做了大量的优化,最核心的有如下三种方式:
- 增加了持久连接;
- 浏览器为每个域名最多同时维护 6 个 TCP 持久连接;
- 使用 CDN 的实现域名分片机制。
HTTP/1.1 中依然存在的问题
虽然 HTTP/1.1 采取了很多优化资源加载速度的策略,也取得了一定的效果,但是 HTTP/1.1 对带宽的利用率却并不理想,这也是 HTTP/1.1 的一个核心问题。
带宽是指每秒最大能发送或者接收的字节数。我们把每秒能发送的最大字节数称为上行带宽,每秒能够接收的最大字节数称为下行带宽。
之所以说 HTTP/1.1 对带宽的利用率不理想,是因为 HTTP/1.1 很难将带宽用满。比如我们常说的 100M 带宽,实际的下载速度能达到 12.5M/S,而采用 HTTP/1.1 时,也许在加载页面资源时最大只能使用到 2.5M/S,很难将 12.5M 全部用满。
之所以会出现这个问题,主要是 3 个问题导致的:
第一个原因,TCP 的慢启动
一旦一个 TCP 连接建立之后,就进入了发送数据状态,刚开始 TCP 协议会采用一个非常慢的速度去发送数据,然后慢慢加快发送数据的速度,直到发送数据的速度达到一个理想状态,我们把这个过程称为慢启动。这个过程可以想象是一辆车的启动过程,开始的时候慢,当速度起来后加速就更快了。
而之所以说慢启动会带来性能问题,是因为页面中常用的一些关键资源文件本来就不大,如 HTML 文件、CSS 文件和 JavaScript 文件,通常这些文件在 TCP 连接建立好之后就要发起请求的,但这个过程是慢启动,所以耗费的时间比正常的时间要多很多,这样就推迟了宝贵的首次渲染页面的时长了。
第二个原因,同时开启了多条 TCP 连接,那么这些连接会竞争固定的带宽
你可以想象一下,系统同时建立了多条 TCP 连接,当带宽充足时,每条连接发送或者接收速度会慢慢向上增加;而一旦带宽不足时,这些 TCP 连接又会减慢发送或者接收的速度。
这样就会出现一个问题,因为有的 TCP 连接下载的是一些关键资源,如 CSS 文件、JavaScript 文件等,而有的 TCP 连接下载的是图片、视频等普通的资源文件,但是多条 TCP 连接之间又不能协商让哪些关键资源优先下载,这样就有可能影响那些关键资源的下载速度了。
第三个原因,HTTP/1.1 队头阻塞的问题
我们知道在 HTTP/1.1 中使用持久连接时,虽然能公用一个 TCP 管道,但是在一个管道中同一时刻只能处理一个请求,在当前的请求没有结束之前,其他的请求只能处于阻塞状态。这意味着我们不能随意在一个管道中发送请求和接收内容。
这是一个很严重的问题,因为阻塞请求的因素有很多,并且都是一些不确定性的因素,假如有的请求被阻塞了 5 秒,那么后续排队的请求都要延迟等待 5 秒,在这个等待的过程中,带宽、CPU 都被白白浪费了。
HTTP/2 的多路复用
为了解决 HTTP/1.1 中存在的问题,在 HTTP/2 中采用最具颠覆性的方案:多路复用机制。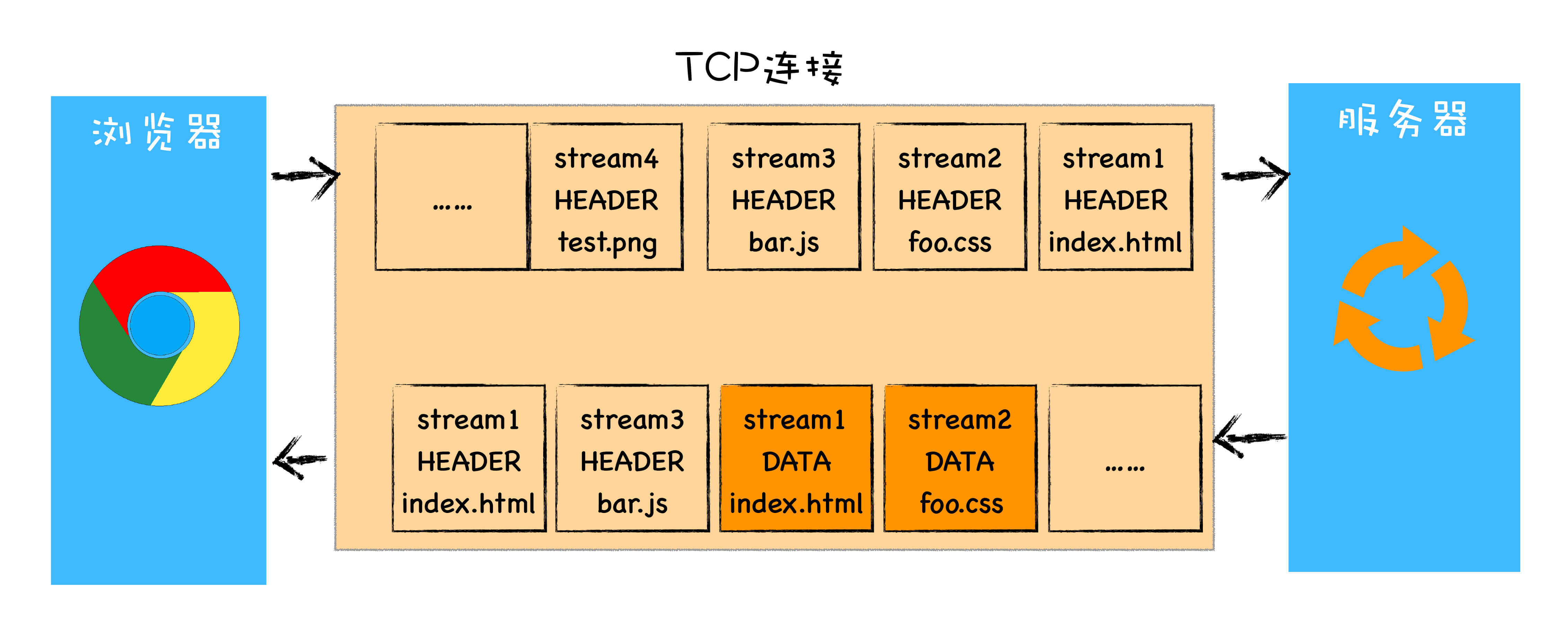
HTTP/2 多路复用是什么
HTTP/2 的多路复用机制用简单的话来说就是浏览器针对同一域名的资源,只建立一个 TCP 连接通道,所有的针对这个域名的请求全部都在这个通道中完成;
除此之外,数据的传输不再使用文本格式,而是会将它们分割为更小的流和帧,并对他们采用二进制格式的编码。在一个 TCP 连接通道中,支持任意数量的双向数据流,这些数据流是并行、乱序的且它们之间互不干扰。而数据流中传输的数据是二进制帧,它是 HTTP/2 中数据传输的最小单位,一个流中的帧是按照顺序传输的,且是并行的,所以无需按顺序等待。
解决了什么问题
因为只使用一个 TCP 连接,所以减少了由于 TCP 慢启动而消耗的时间,另外也由于只有单条 TCP 连接,所以不存在不同的 TCP 争夺网络带宽的问题。
客户端发送的请求经过二进制分帧层后,不再是一个个完整的 HTTP 请求报文,而是一堆乱序的帧(即不同流的帧是乱的,但是同一条流的帧数顺序传输的),所以就不会按顺序传输,也就不存在等待,从而解决了 HTTP 对头阻塞问题。
是如何实现的
- 首先,浏览器准备好请求数据,包括了请求行、请求头等信息,如果是 POST 方法,那么还要有请求体。
- 这些数据经过二进制分帧层处理之后,会被转换为一个个带有请求 ID 编号的帧,通过协议栈将这些帧发送给服务器。请求头的信息存在 header 帧中,而请求体数据存在 data 帧中。
- 服务器接收到所有帧之后,会将所有相同 ID 的帧合并为一条完整的请求信息。
- 然后服务器处理该条请求,并将处理的响应行、响应头和响应体分别发送至二进制分帧层。
- 同样,二进制分帧层会将这些响应数据转换为一个个带有请求 ID 编号的帧,经过协议栈发送给浏览器。
- 浏览器接收到响应帧之后,会根据 ID 编号将帧的数据提交给对应的请求。
HTTP/2 其他特性
1. 可以设置请求的优先级
在浏览器中,某些数据是非常重要的,比如关键 CSS 或者 JS,这些重要的数据如果比较晚才推送到浏览器,那么对用户来说肯定是一个不好的体验。
所以 HTTP/2 中可以支持设置请求的优先级,这样服务器收到高优先级的请求后,会优先处理。
2. 服务器推送
在 HTTP/2 中服务器解析到一个 HTML 页面后,服务器知道浏览器需要这个页面上引用到的资源,比如 CSS 和 JS,那么服务器就会主动的把这些资源一并推送给浏览器,减少客户端的等待时间。
3. 头部压缩
HTTP/2 使用 HPACK 压缩算法对请求头和响应头进行压缩,虽然单个请求压缩之后效果不是很明显,但是如果一个页面有 100 个请求,那每个请求压缩 20% 之后,那提速效果就很明显了。
而 HPACK 的压缩原理其实就是 2 点:
- 它要求客户端和服务器两者都维护和更新先前看到的报头字段的索引列表(即,建立共享的压缩上下文),然后将该列表用作有效编码先前传输的值的参考。在实际传输的时候用索引代替每一侧的静态或动态表中已经存在的字段,从而减小每个请求的大小。
- 它允许通过静态霍夫曼码对发送的标头字段进行编码,从而减小了它们各自的传输大小。
HTTP/3
HTTP/2 依然是基于 TCP 的,所以还存在以下一些问题。
TCP 的队头阻塞
HTTP/2 中多个请求是跑在一个 TCP 连接中的,如果某个数据流中出现了丢包的情况,就会阻塞该 TCP 连接中的所有请求。这个和 HTTP/1.1 中的不同,在 HTTP/1.1 中,由于浏览器为每个域名建立了 6 个 TCP 连接,如果其中一个 TCP 连接发生了队头阻塞,那么其他的 5 个连接依然可以继续传输数据。
TCP 建立连接的延时
在传输数据之前,需要进行 TCP 的 3 次握手,需要花费 1.5 个 RTT;如果是 HTTPS,那还需要进行 TLS 连接,又需要 1 ~ 2 个 RTT。
网络延迟又叫 RTT(Round Trip Time),是从浏览器发送一个数据包到服务器,再从服务器返回数据包到浏览器的整个往返时间。
总之,在传输数据之前需要花掉 3 ~ 4 个 RTT。如果客户端和服务器距离近的话,那 1 个 RTT 大概是 10ms,但如果远的话,可能是 100ms,所以传输数据之前需要花掉 300ms 左右,这个时候就能感觉到慢了。
TCP 协议僵化
我们知道 TCP 协议存在队头阻塞和建立连接延迟的问题,但是又没办法改进 TCP 协议,理由有如下 2 个:
- 中间设备僵化。中间设备比如路由器、交换机、防火墙和 NAT 等,这些设备依赖的软件使用了大量的 TCP 特性,一旦功能被设置后就很少进行更新了。如果在客户端进行升级 TCP 协议,那么当新协议的数据包经过这些设备的时候,可能会不理解包的内容,造成数据丢失。
- 操作系统也是导致 TCP 协议僵化的另外一个原因。
QUIC 协议
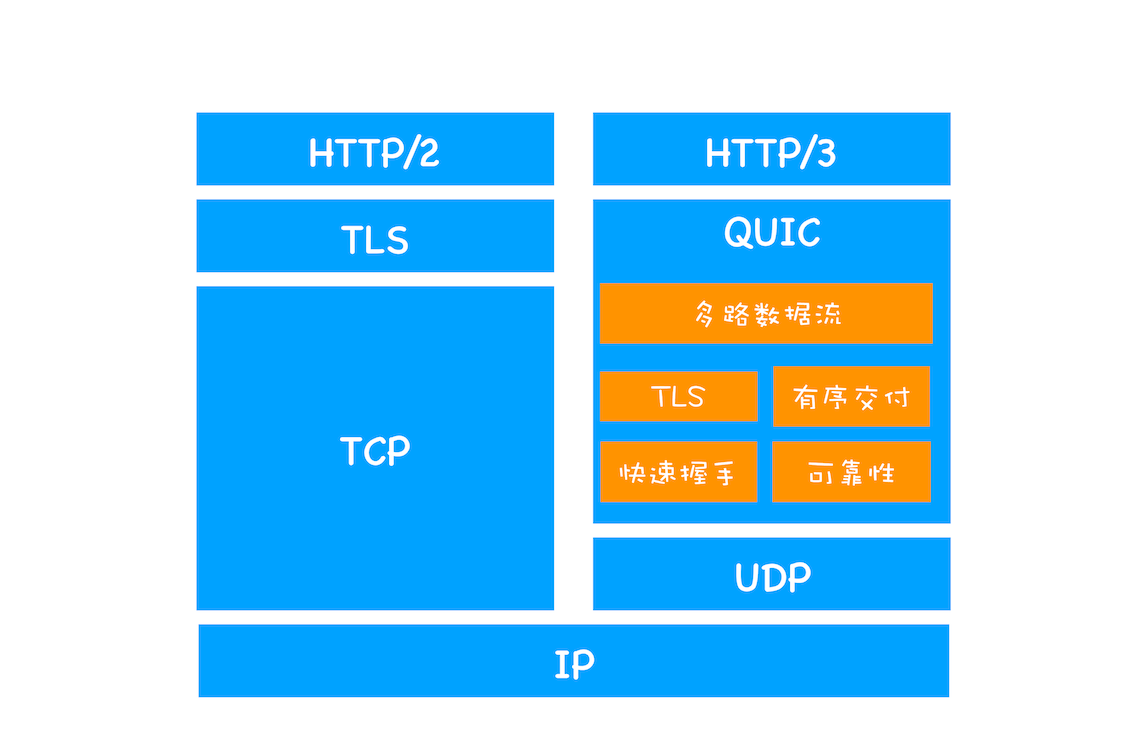
HTTP/3 是基于 UDP 实现的,实现了类似于 TCP 的多路数据流、传输可靠性等功能,我们把这套功能称为 QUIC 协议。
- 实现了类似 TCP 的流量控制、传输可靠性的功能。虽然 UDP 不提供可靠性的传输,但 QUIC 在 UDP 的基础之上增加了一层来保证数据可靠性传输。它提供了数据包重传、拥塞控制以及其他一些 TCP 中存在的特性。
- 集成了 TLS 加密功能。目前 QUIC 使用的是 TLS1.3,相较于早期版本 TLS1.3 有更多的优点,其中最重要的一点是减少了握手所花费的 RTT 个数。
- 实现了 HTTP/2 中的多路复用功能。和 TCP 不同,QUIC 实现了在同一物理连接上可以有多个独立的逻辑数据流(如下图)。实现了数据流的单独传输,就解决了 TCP 中队头阻塞的问题。
- 实现了快速握手功能。由于 QUIC 是基于 UDP 的,所以 QUIC 可以实现使用 0-RTT 或者 1-RTT 来建立连接,这意味着 QUIC 可以用最快的速度来发送和接收数据,这样可以大大提升首次打开页面的速度。
HTTP/3 的挑战
- 第一,从目前的情况来看,服务器和浏览器端都没有对 HTTP/3 提供比较完整的支持。Chrome 虽然在数年前就开始支持 Google 版本的 QUIC,但是这个版本的 QUIC 和官方的 QUIC 存在着非常大的差异。
- 第二,部署 HTTP/3 也存在着非常大的问题。因为系统内核对 UDP 的优化远远没有达到 TCP 的优化程度,这也是阻碍 QUIC 的一个重要原因。
- 第三,中间设备僵化的问题。这些设备对 UDP 的优化程度远远低于 TCP,据统计使用 QUIC 协议时,大约有 3%~ 7% 的丢包率。