「建议收藏」送你一份精心总结的3万字ES6实用指南(全)
次访问
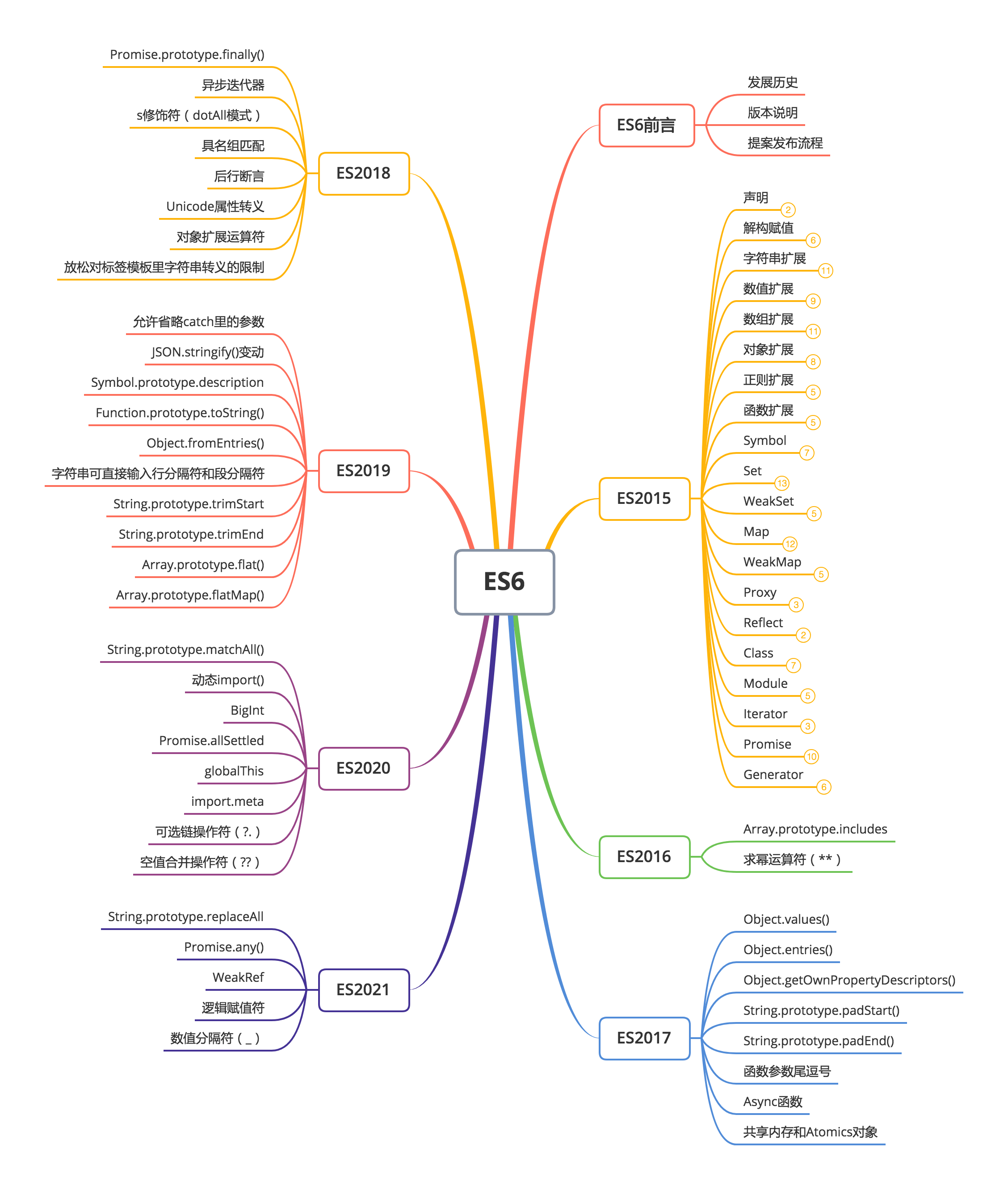
写本篇文章目的是为了夯实基础,基于阮一峰老师的著作 ECMAScript 6 入门 以及 tc39-finished-proposals 这两个知识线路总结提炼出来的重点和要点,涉及到从 ES2015 到 ES2021 的几乎所有知识,基本上都是按照一个知识点配上一段代码的形式来展示,所以篇幅较长,也正是因为篇幅过长,所以就没把 Stage 2 和 Stage 3 阶段的提案写到这里,后续 ES2021 更新了我再同步更新。
有 5 个提案已经列入 Expected Publication Year in 2021 所以本篇中暂且把他们归为 ES2021。
ES6 前言
发展史
能写好 JS 固然是重要的,但是作为一个前端,我们也要了解自己所使用语言的发展历程,这里强烈推荐看 《JavaScript 20 年》,本书详细记载和解读了自 1995 年语言诞生到 2015 年 ES6 规范制定为止,共计 20 年的 JavaScript 语言演化历程。
版本说明
2011 年,发布了 ECMAScript 5.1 版,而 2015 年 6 月发布了 ES6 的第一个版本又叫 ES2015。ES6 其实是一个泛指,指代 5.1 版本以后的下一代标准。TC39 规定将于每年的 6 月发布一次正式版本,版本号以当年的年份为准,比如当前已经发布了 ES2015、ES2016、ES2017、ES2018、ES2019、ES2020 等版本。
提案发布流程
任何人都可以向 TC39 提案,要求修改语言标准。一种新的语法从提案到变成正式标准,需要经历五个阶段。每个阶段的变动都需要由 TC39 委员会批准。
Stage 0-Strawperson(展示阶段)Stage 1-Proposal(征求意见阶段)Stage 2-Draft(草案阶段)Stage 3-Candidate(候选人阶段)Stage 4-Finished(定案阶段)
一个提案只要能进入 Stage 2,就差不多肯定会包括在以后的正式标准里面。ECMAScript 当前的所有提案,可以在这里查看 ecma262。关于提案流程可以在这里 TC39_Process 看到更加详细的信息。
ES2015
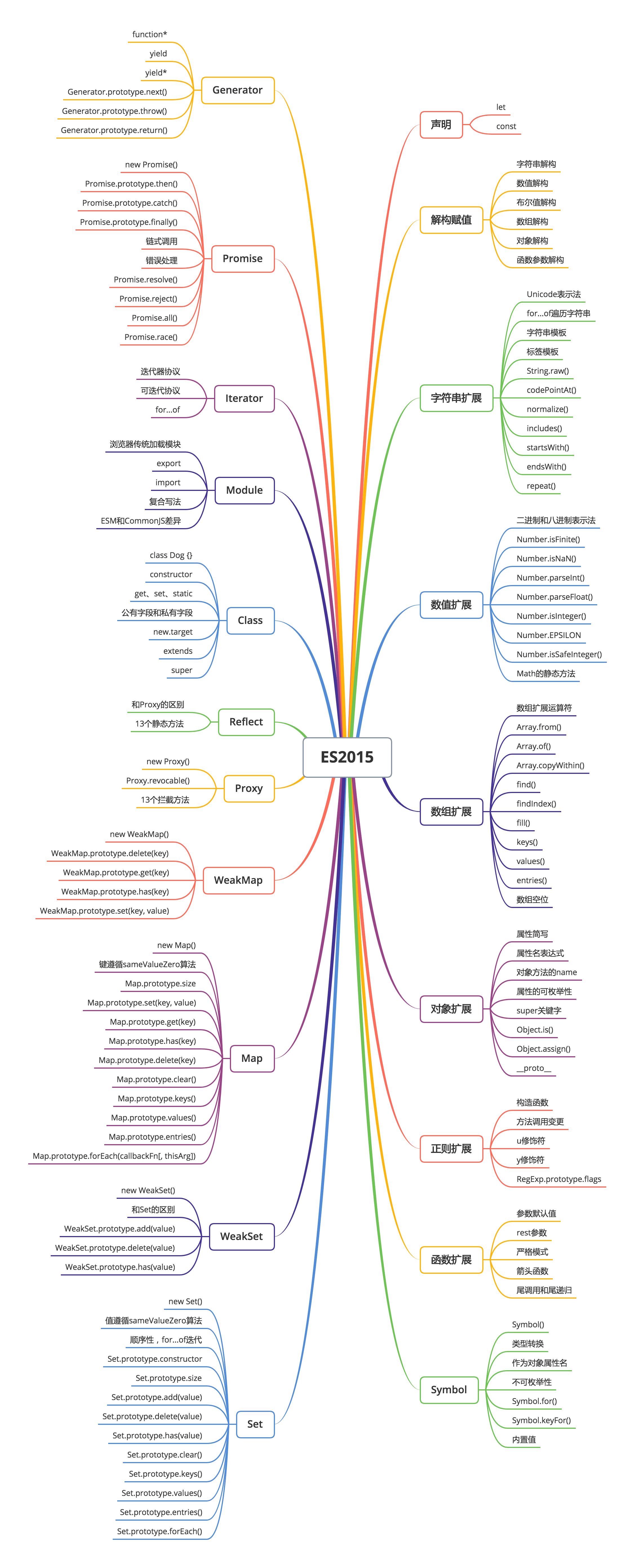
声明
const:声明一个常量,let:声明一个变量;const/let 声明的常量/变量都只能作用于代码块(块级作用域或函数作用域)里;
1 | if (true) { |
const/let 不存在变量提升,所以在代码块里必须先声明然后才可以使用,这叫暂时性死区;
1 | let name = 'bubuzou' |
const/let 不允许在同一个作用域内,重复声明;
1 | function setName(name) { |
const 声明时必须初始化,且后期不能被修改,但如果初始化的是一个对象,那么不能修改的是该对象的内存地址;
1 | const person = { |
const/let 在全局作用域中声明的常量/变量不会挂到顶层对象(浏览器中是 window )的属性中;
1 | var name = '布兰' |
解构赋值
解构类型:
字符串解构
1
2let [a, b, c = 'c'] = '12'
console.log(a, b, c) // '1' '2' 'c'数值解构
1
2let { toFixed: tf } = 10
console.log(tf.call(Math.PI, 2)) // 3.14布尔值解构
1
2let { toString: ts } = true
console.log(ts.call(false)) // 'false'数组解构:等号右侧的数据具有
Iterator接口可以进行数组形式的解构赋值;1
2
3
4
5
6
7// 解构不成功的变量值为 undefined
let [a, b, c] = [1, 2]
console.log(a, b, c) // 1, 2, undefined
// 可以设置默认值
let [x, y, z = 3] = [1, 2, null]
console.log(x, y, z) // 1, 2, null什么样的数据具有
Iterator接口呢?如果一个对象能够通过 [Symbol.iterator] 访问,且能够返回一个符合迭代器协议的对象,那么该对象就是可迭代的。目前内置的可迭代对象有:String、Array、TypeArray、Map、Set、arguments 和 NodeList 等。对象解构:与数组按照索引位置进行解构不同,对象解构是按照属性名进行解构赋值,如果在当前对象属性匹配不成功则会去对象的原型属性上查找:
1
2// 默认写法
let { name: name, age: age } = { name: '布兰', age: 12 }1
2// 简写
let { name, age } = { name: '布兰', age: 12 }1
2
3// 改名且设置默认值
let { name: name1, age: age1 = 12 } = { name: '布兰' }
console.log(name1, age1) // '布兰' 12函数参数解构:其实就是运用上面的对象解构和数组解构规则;
1
2
3
4
5
6
7
8function move({ x = 0, y = 0 } = {}) {
console.log([x, y])
return [x, y]
}
move({ x: 3, y: 8 }) // [3, 8]
move({ x: 3 }) // [3, 0]
move({}) // [0, 0]
move() // [0, 0]
解构要点:
- 只要等号两边的模式相同(同是对象或同是数组),则左边的变量会被赋予对应的值;
- 解构不成功的变量值为
undefined; - 默认值生效的前提是当等号右边对应的值全等于 undefined 的时候;
- 只要等号右边的值不是对象或者数组,则会进行自动装箱将其转成对象;
null和undefined都无法转成对象,所以无法解构。
解构应用:
交换变量的值;
1
2
3
4let x = 1,
y = 2
;[x, y] = [y, x]
console.log(x, y) // 2 1通过函数返回对象属性
1
2
3
4
5
6
7function getParams() {
return {
name: '布兰',
age: 12,
}
}
let { name, age } = getParams()通过定义函数参数来声明变量
1
2
3
4
5
6
7
8
9
10
11
12
13let person = {
name: '布兰',
age: 12,
}
init(person)
// 普通用法
function init(person) {
let { name, age } = person
}
// 更简洁用法
function init({ name, age }) {}指定函数参数默认值
1
2
3
4
5function initPerson({ name = '布兰', age = 12 } = {}) {
console.log(name, age)
}
initPerson() // '布兰' 12
initPerson({ age: 20 }) // '布兰' 20提取
JSON数据1
2
3
4
5
6
7let responseData = {
code: 1000,
data: {},
message: 'success',
}
let { code, data = {} } = responseData遍历 Map 结构
1
2
3
4
5
6
7let map = new Map()
map.set('beijing', '北京')
map.set('xiamen', '厦门')
for (let [key, value] of map) {
console.log(key, value)
}输入模块的指定方法和属性
1
const { readFile, writeFile } = require('fs')
字符串扩展
可以使用
Unicode编码来表示一个字符:1
2
3
4
5
6// 以下写法都可以用来表示字符 z
'\z' // 转义
'\172' // 十进制表示法
'\x7A' // 十六进制表示法
'\u007A' // Unicode 普通表示法
'\u{7A}' // Unicode 大括号表示法www.52unicode.com 这个网站可以查询到常见符号的 Unicode 编码。
可以使用
for...of正确遍历字符串:1
2
3
4
5
6
7let str = '😀🤣😜😍🤗🤔'
for (const emoji of str) {
console.log(emoji) // 😀🤣😜😍🤗🤔
}
for (let i = 0, l = str.length; i < l; i++) {
console.log(str[i]) // 不能正确输出表情
}模板字符串使用两个反引号标识(``),可以用来定义多行字符串,或者使用它在字符串中插入变量:
1
2
3
4let name = 'hero'
let tips = `Hello ${name},
welcome to my world.`
alert(tips)标签模板:在函数名后面接一个模板字符串相当于给函数传入了参数进行调用:
1
2
3
4
5
6
7let name = '布兰',
age = 12
let tips = parse`Hello ${name}, are you ${age} years old this year?`
function parse(stringArr, ...variable) {}
// 相当于传递如下参数进行调用 parse 函数
parse(['Hello ', ', are you ', ' years old this year?'], name, age)String.fromCodePoint()用于从Unicode码点返回对应字符,可以支持0xFFFF的码点:1
2String.fromCharCode(0x1f600) // ""
String.fromCodePoint(0x1f600) // "😀"String.raw()返回把字符串所有变量替换且对斜杠进行转义的结果:1
String.raw`Hi\n${2 + 3}!` // "Hi\n5!"
codePointAt()返回字符的十进制码点,对于Unicode大于0xFFFF的字符,会被认为是 2 个字符,十进制码点转成十六进制可以使用toString(16):1
2
3
4
5
6let emoji = '🤣'
emoji.length // 2
emoji.charCodeAt(0).toString(16) // 'd83d'
emoji.charCodeAt(1).toString(16) // 'de00'
String.fromCodePoint(0xd83d, 0xde00) === '🤣' // truenormalize()方法会按照指定的一种Unicode正规形式将当前字符串正规化。(如果该值不是字符串,则首先将其转换为一个字符串):1
2
3
4
5
6
7
8let str1 = '\u00F1'
let str2 = '\u006E\u0303'
str1 // ñ
str2 // ñ
str1 === str2 // false
str1.length === str2.length // false
str1.normalize() === str2.normalize() // true字符串是否包含子串:
- includes():返回布尔值,表示是否找到了参数字符串。
- startsWith():返回布尔值,表示参数字符串是否在原字符串的头部。
- endsWith():返回布尔值,表示参数字符串是否在原字符串的尾部。
1
2
3
4
5let s = 'Hello world!'
s.includes('o') // true
s.startsWith('Hello') // true
s.endsWith('!') // true这三个方法都支持第二个参数,表示开始搜索的位置:
1
2
3
4
5let s = 'Hello world!'
s.includes('Hello', 6) // false
s.startsWith('world', 6) // true
s.endsWith('Hello', 5) // true上面代码表示,使用第二个参数
n时,endsWith的行为与其他两个方法有所不同。它针对前n个字符,而其他两个方法针对从第n个位置直到字符串结束。repeat(n)将当前字符串重复n次后,返回一个新字符串:1
2
3
4
5
6
7
8'x'.repeat(2) // 'xx'
'x'.repeat(1.9) // 'x'
'x'.repeat(NaN) // ''
'x'.repeat(undefined) // ''
'x'.repeat('2a') // ''
'x'.repeat(-0.6) // '',解释:0 ~ 1 之间的小数相当于 0
'x'.repeat(-2) // RangeError
'x'.repeat(Infinity) // RangeError
数值扩展
二进制(0b)和八进制(0o)表示法:
1
2
3
4
5let num = 100
let b = num.toString(2) // 二进制的100:1100100
let o = num.toString(8) // 八进制的100:144
0b1100100 === 100 // true
0o144 === 100 // trueNumber.isFinite()判断一个数是否是有限的数,入参如果不是数值一律返回false:1
2
3
4
5Number.isFinite(-2.9) // true
Number.isFinite(NaN) // false
Number.isFinite('') // false
Number.isFinite(false) // true
Number.isFinite(Infinity) // falseNumber.isNaN()判断一个数值是否为NaN,如果入参不是NaN那结果都是false:1
2
3Number.isNaN(NaN) // true
Number.isFinite('a' / 0) // true
Number.isFinite('NaN') // false数值转化:
Number.parseInt()和Number.parseFloat(),非严格转化,从左到右解析字符串,遇到非数字就停止解析,并且把解析的数字返回:1
2
3
4parseInt('12a') // 12
parseInt('a12') // NaN
parseInt('') // NaN
parseInt('0xA') // 10,0x开头的将会被当成十六进制数parseInt()默认是用十进制去解析字符串的,其实他是支持传入第二个参数的,表示要以多少进制的 基数去解析第一个参数:1
2parseInt('1010', 2) // 10
parseInt('ff', 16) // 255参考:parseInt
Number.isInteger()判断一个数值是否为整数,入参为非数值则一定返回false:1
2
3
4
5
6
7Number.isInteger(25) // true
Number.isInteger(25.0) // true
Number.isInteger() // false
Number.isInteger(null) // false
Number.isInteger('15') // false
Number.isInteger(true) // false
Number.isInteger(3.0000000000000002) // true如果对数据精度的要求较高,不建议使用 Number.isInteger() 判断一个数值是否为整数。
Number.EPSILON表示一个可接受的最小误差范围,通常用于浮点数运算:1
20.1 + 0.2 === 0.3 // false
Math.abs(0.1 + 0.2 - 0.3) < Number.EPSILON // trueNumber.isSafeInteger()用来判断一个数是否在最大安全整数(Number.MAX_SAFE_INTEGER)和最小安全整数(Number.MIN_SAFE_INTEGER)之间:1
2
3
4
5
6Number.MAX_SAFE_INTEGER === 2 ** 53 - 1 // true
Number.MAX_SAFE_INTEGER === 9007199254740991 // true
Number.MIN_SAFE_INTEGER === -Number.MAX_SAFE_INTEGER // true
Number.isSafeInteger(2) // true
Number.isSafeInteger('2') // false
Number.isSafeInteger(Infinity) // falseMath.trunc():返回数值整数部分Math.sign():返回数值类型(正数 1、负数 -1、零 0)Math.cbrt():返回数值立方根Math.clz32():返回数值的 32 位无符号整数形式Math.imul():返回两个数值相乘Math.fround():返回数值的 32 位单精度浮点数形式Math.hypot():返回所有数值平方和的平方根Math.expm1():返回e^n - 1Math.log1p():返回 1 + n 的自然对数(Math.log(1 + n))Math.log10():返回以 10 为底的 n 的对数Math.log2():返回以 2 为底的 n 的对数Math.sinh():返回 n 的双曲正弦Math.cosh():返回 n 的双曲余弦Math.tanh():返回 n 的双曲正切Math.asinh():返回 n 的反双曲正弦Math.acosh():返回 n 的反双曲余弦Math.atanh():返回 n 的反双曲正切
数组扩展
数组扩展运算符(…)将数组展开成用逗号分隔的参数序列,只能展开一层数组:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// 应用一:函数传参
Math.max(...[1, 2, 3]) // 3
// 应用二:数组合并
let merge = [...[1, 2], ...[3, 4], 5, 6] // 1, 2, 3, 4, 5, 6
// 应用三:浅克隆
let a = [1, 2, 3]
let clone = [...a]
a === clone // false
// 应用四:数组解构
const [x, ...y] = [1, 2, 3]
x // 1
y // [2, 3]Array.from()可以将类数组对象(NodeList,arguments)和可迭代对象转成数组:1
2
3
4
5
6
7
8
9
10
11
12// 应用一:字符串转数组
Array.from('foo') // ['f', 'o', 'o']
// 应用二:数组合并去重
let merge = [...[1, 2], ...[2, 3]]
Array.from(new Set(merge)) // ['1', '2', '3']
// 应用三:arguments 转数组
function f() {
return Array.from(arguments)
}
f(1, 2, 3) // [1, 2, 3]如果
Array.from()带第二个参数mapFn,将对生成的新数组执行一次map操作:1
2Array.from([1, 2, 3], (x) => x * x) // [1, 4, 9]
Array.from({ length: 3 }, (v, i) => ++i) // [1, 2, 3]Array.of()将一组参数转成数组:1
2
3
4
5
6
7Array.of(1, 2, 3) // [1, 2, 3]
// 类似于
function arrayOf(...params) {
return [].slice.call(params)
}
arrayOf(1, 2, 3) // [1, 2, 3]Array.copyWithin()在当前数组内部,将制定位置的成员复制到其他位置(会覆盖原来位置的成员),最后返回一个新数组。接收 3 个参数,参数为负数表示右边开始计算:target(必选):替换位置的索引;start(可选):从该位置开始读取数据,默认为 0;end(可选):从该位置结束读取数据(不包括该位置的数据),默认为原数组长度;
1
2
3
4
5;[1, 2, 3, 4, 5]
.copyWithin(-1) // [1, 2, 3, 4, 1]
[(1, 2, 3, 4, 5)].copyWithin(1) // [1, 1, 2, 3, 4]
[(1, 2, 3, 4, 5)].copyWithin(0, 3, 4) // [4, 2, 3, 4, 5]
[(1, 2, 3, 4, 5)].copyWithin(0, -3, -1) // [3, 4, 3, 4, 5]查找第一个出现的子成员:
find()和findIndex():1
2
3
4
5
6
7
8// 找出第一个偶数
;[1, 6, 9]
.find((val, index, arr) => val % 2 === 0) // 6
[
// 找出第一个偶数的索引位置
(1, 6, 9)
].findIndex((val, index, arr) => val % 2 === 0) // 1fill()使用给定的值来填充数组,有 3 个参数:value:填充值;start(可选),开始索引,默认为 0;end(可选):结束索引,默认为数组长度,不包括该索引位置的值;
1
2
3
4
5// 初始化空数组
Array(3)
.fill(1) // [1, 1, 1]
[(1, 2, 3, 4)].fill('a', 2, 4) // [1, 2, 'a', 'a']通过
keys()(键名)、entries()(键值)和values()(键值对) 获取数组迭代器对象,可以被for...of迭代,1
2
3
4
5
6
7
8
9
10let arr = ['a', 'b', 'c']
for (let x of arr.keys()) {
console.log(x) // 1, 2, 3
}
for (let v of arr.values()) {
console.log(v) // 'a' 'b' 'c'
}
for (let e of arr.entries()) {
console.log(e) // [0, 'a'] [0, 'b'] [0, 'c']
}数组空位,是指数组没有值,比如:
[,,],而像这种[undefined]是不包含空位的。由于ES6之前的一些API对空位的处理规则很不一致,所以实际操作的时候应该尽量避免空位的出现,而为了改变这个现状,ES6的API会默认将空位处理成undefined:1
2[...[1, , 3].values()] // [1, undefined, 3]
[1, , 3].findIndex(x => x === undefined) // 1
对象扩展
对象属性简写:
1
2
3
4
5
6
7
8
9
10
11
12
13
14let name = '布兰'
let person = {
name,
getName() {
return this.name
},
}
// 等同于
let person1 = {
name: '布兰',
getName: function () {
return this.name
},
}属性名表达式:在用对象字面量定义对象的时候,允许通过属性名表达式来定义对象属性:
1
2
3
4
5
6
7let name = 'name',
let person = {
[name]: '布兰',
['get'+ name](){
return this.name
}
}方法的
name属性,存在好几种情况,这里仅列出常见的几种:情况一:普通对象方法的
name属性直接返回方法名,函数声明亦是如此,函数表达式返回变量名:1
2
3
4let person = {
hi() {},
}
person.hi.name // 'hi'情况二:构造函数的
name为anonymous:1
new Function().name // 'anonymous'
情况三:绑定函数的
name将会在函数名前加上bound:1
2function foo() {}
foo.bind({}).name // 'bound foo'情况四:如果对象的方法使用了取值函数(
getter)和存值函数(setter),则name属性不是在该方法上面,而是该方法的属性的描述对象的get和set属性上面:1
2
3
4
5
6
7
8let o = {
get foo() {},
set foo(x) {},
}
o.foo.name // TypeError: Cannot read property 'name' of undefined
let descriptor = Object.getOwnPropertyDescriptor(o, 'foo')
descriptor.get.name // "get foo"
descriptor.set.name // "set foo"属性的可枚举性
对象的每个属性都有一个描述对象(
Descriptor),用来控制该属性的行为。可以通过Object.getOwnPropertyDescriptor()来获取对象某个属性的描述:1
2
3
4
5
6
7
8let person = { name: '布兰', age: 12 }
Object.getOwnPropertyDescriptor(person, 'name')
// {
// configurable: true,
// enumerable: true,
// value: "布兰",
// writable: true,
// }这里的
enumerable就是对象某个属性的可枚举属性,如果某个属性的enumerable值为false则表示该属性不能被枚举,所以该属性会被如下 4 种操作忽略:for...in:只遍历对象自身的和继承的可枚举的属性;Object.keys():返回对象自身的所有可枚举的属性的键名;JSON.stringify():只串行化对象自身的可枚举的属性;Object.assign(): 只拷贝对象自身的可枚举的属性。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16let person = { name: '布兰' }
Object.defineProperty(person, 'age', {
configurable: true,
enumerable: false,
value: 12,
writable: true,
})
person // { name: '布兰', age: 12 }
// 以下操作都将忽略 person 对象的 age 属性
for (let x in person) {
console.log(x) // 'name'
}
Object.keys(person) // ['name']
JSON.stringify(person) // '{"name": "布兰"}'
Object.assign({}, person) // { name: '布兰' }Reflect.ownKeys(obj): 返回一个数组,包含对象自身的(不含继承的)所有键名,不管键名是Symbol或字符串,也不管是否可枚举:1
2// 基于上面的代码
Reflect.ownKeys(person) // ['name', 'age']super关键字,指向对象的原型对象,只能用于对象的方法中,其他地方将报错:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21let person = {
name: '布兰',
getName() {
return super.name
},
}
Object.setPrototypeOf(person, { name: 'hello' })
person.getName() // 'hello'
// 以下几种 super 的使用将报错
const obj1 = {
foo: super.foo,
}
const obj2 = {
foo: () => super.foo,
}
const obj3 = {
foo: function () {
return super.foo
},
}Object.is()用来判断两个值是否相等,表现基本和===一样,除了以下两种情况:1
2
3
4;+0 === -0 //true
NaN === NaN // false
Object.is(+0, -0) // false
Object.is(NaN, NaN) // trueObject.assign()用于对象的合并,将源对象(source)的所有可枚举属性,复制到目标对象(target),如果有同名属性,则后面的会直接替换前面的:1
2
3
4
5let target = { a: 1 }
let source1 = { a: 2, b: 3, d: { e: 1, f: 2 } }
let source2 = { a: 3, c: 4, d: { g: 3 } }
Object.assign(target, source1, source2)
target // { a: 3, b: 3, c: 4, d: {g: 3} }Object.assign()实行的是浅拷贝,如果源对象某个属性是对象,那么拷贝的是这个对象的引用:1
2
3
4
5let target = { a: { b: 1 } }
let source = { a: { b: 2 } }
Object.assign(target, source)
target.a.b = 3
source.a.b // 3__proto__属性是用来读取和设置当前对象的原型,而由于其下划线更多的是表面其是一个内部属性,所以建议不在正式场合使用它,而是用下面的Object.setPrototypeOf()(写操作)、Object.getPrototypeOf()(读操作)、Object.create()(生成操作)代替。Object.setPrototypeOf()用于设置对象原型,Object.getPrototypeOf()用于读取对象原型:1
2
3let person = { name: '布兰' }
Object.setPrototypeOf(person, { name: '动物' })
Object.getPrototypeOf(person) // {name: '动物'}
正则扩展
RegExp构造函数,允许首参为正则表达式,第二个参数为修饰符,如果有第二个参数,则修饰符以第二个为准:1
2let reg = new RegExp(/xYz\d+/gi, i)
reg.flags // 'i'正则方法调用变更:字符串对象的
match()、replace()、search()、split()内部调用转为调用RegExp实例对应的RegExp.prototype[Symbol.方法];u修饰符:含义为Unicode模式,用来正确处理大于\uFFFF的Unicode字符。也就是说,如果待匹配的字符串中可能包含有大于\uFFFF的字符,就必须加上u修饰符,才能正确处理。1
2
3
4
5
6
7
8
9
10
11// 加上 u 修饰符才能让 . 字符正确识别大于 \uFFFF 的字符
/^.$/.test('🤣') // false
/^.$/u.test('🤣') // true
// 大括号 Unicode 字符表示法必须加上 u 修饰符
/\u{61}/.test('a') // false
/\u{61}/u.test('a') // true
// 有 u 修饰符,量词才能正确匹配大于 \uFFFF 的字符
/🤣{2}/.test('🤣🤣') // false
/🤣{2}/u.test('🤣🤣') // trueRegExp.prototype.unicode属性表示正则是否设置了u修饰符:1
2/🤣/.unicode // false
/🤣/u.unicode // truey修饰符,与g修饰符类似也是全局匹配;不同的是g是剩余字符中匹配即可,而y则是必须在剩余的第一个字符开始匹配才行,所以y修饰符也叫黏连修饰符:1
2
3
4
5
6
7
8
9let s = 'aaa_aa_a'
let r1 = /a+/g
let r2 = /a+/y
r1.exec(s) // ["aaa"]
r2.exec(s) // ["aaa"]
r1.exec(s) // ["aa"]
r2.exec(s) // nullRegExp.prototype.sticky属性表示是否设置了y修饰符:1
;/abc/y.sticky // true
RegExp.prototype.flags属性会返回当前正则的所有修饰符:1
;/abc🤣/iuy.flags // 'iuy'
函数扩展
函数参数默认值。参数不能有同名的,函数体内不能用
let和const声明同参数名的变量:1
function printInfo(name = '布兰', age = 12) {}
使用参数默认值的时候,参数不能有同名的:
1
2function f(x, x, y) {} // 不报错
function f(x, x, y = 1) {} // 报错函数体内不能用
let和const声明同参数名的变量:1
2
3
4// 报错
function f(x, y) {
let x = 0
}函数的
length属性会返回没有指定默认值的参数个数,且如果设置默认值的参数不是尾参数,则length不再计入后面的参数:1
2
3
4
5
6
7
8
9;(function f(x, y) {}
.length(
// 2
function f(x, y = 1) {}
)
.length(
// 1
function f(x = 1, y) {}
).length) // 0剩余(
rest) 参数(…变量名)的形式,用于获取函数的剩余参数,注意rest参数必须放在最后一个位置,可以很好的代替arguments对象:1
2
3
4
5
6
7function f(x, ...y) {
console.log(x) // 1
for (let val of y) {
coonsole.log(val) // 2 3
}
}
f(1, 2, 3)严格模式:只要函数参数使用了默认值、解构赋值或者扩展运算符,那么函数体内就不能显示的设定为严格模式,因为严格模式的作用范围包含了函数参数,而函数执行的顺序是先执行参数,然后再执行函数体,执行到函数体里的
use strict的时候,那么此时因为函数参数已经执行完成了,那函数参数还要不要受到严格模式的限制呢?这就出现矛盾了。规避限制的办法有两个:设置全局的严格模式或者在函数体外在包一个立即执行函数并且声明严格模式:1
2
3
4
5
6
7
8
9// 解法一
function f(x, y = 2) {}
// 解法二
let f = (function () {
return function (x, y = 2) {}
})()箭头函数语法比函数表达式更简洁,并且没有自己的
this、arguments,不能用作构造函数和用作生成器。
几种箭头函数写法:1
2
3
4
5
6
7let f1 = () => {} // 没有参数
let f2 = (x) => {} // 1个参数
let f3 = (x) => {} // 1个参数可以省略圆括号
let f4 = (x, y) => {} // 2个参数以上必须加上圆括号
let f5 = (x = 1, y = 2) => {} // 支持参数默认值
let f6 = (x, ...y) => {} // 支持 rest 参数
let f7 = ({ x = 1, y = 2 } = {}) // 支持参数解构箭头函数没有自己的
this:1
2
3
4
5
6
7function Person() {
this.age = 0
setInterval(() => {
this.age++
}, 1000)
}
var p = new Person() // 1 秒后 Person {age: 1}通过
call/apply调用箭头函数的时候将不会绑定第一个参数的作用域:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16let adder = {
base: 1,
add: function (a) {
let f = (v) => v + this.base
return f(a)
},
addThruCall: function (a) {
let f = (v) => v + this.base
let b = {
base: 2,
}
return f.call(b, a)
},
}
adder.add(1) // 输出 2
adder.addThruCall(1) // 仍然输出 2箭头函数没有自己的
arguments对象,不过可以使用rest参数代替:1
2
3
4
5
6
7
8
9
10let log = () => {
console.log(arguments) // ReferenceError
}
log(2, 3)
// 剩余参数代替写法
let restLog = (...arr) => {
console.log(arr) // [2, 3]
}
restLog(2, 3)箭头函数不能用作构造器,和
new一起用会抛出错误:1
2
3let Foo = () => {}
let foo = new Foo()
// TypeError: Foo is not a constructor箭头函数返回对象字面量,需要用圆括号包起来:
1
let func2 = () => ({ foo: 1 })
尾调用和尾递归
首先得知道什么是尾调用:函数的最后一步调用另外一个函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// 是尾调用
function f(x) {
return g(x)
}
// 以下都不是尾调用
function f(x) {
let y = g(x)
return y
}
function f(x) {
let y = g(x)
return g(x) + 1
}
function f(x) {
g(x)
// 因为最后一步是 return: undefined
}尾调用有啥用?我们知道函数的相互调用是会生成“调用帧”的,而“调用帧”里存了各种信息比如函数的内部变量和调用函数的位置等,所有的“调用帧”组成了一个“调用栈”。如果在函数的最后一步操作调用了另外一个函数,因为外层函数里调用位置、内部变量等信息都不会再用到了,所有就无需保留外层函数的“调用帧”了,只要直接用内层函数的“调用帧”取代外层函数的“调用帧”即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15function f() {
let m = 1
let n = 2
return g(m + n)
}
f()
// 等同于
function f() {
return g(3)
}
f()
// 等同于
g(3)这样一来就很明显的减少了调用栈中的帧数,内存占用就少了,所以这就是尾调用的优化作用。尾递归也是如此,递归如果次数多那就需要保留非常多的“调用帧”,所以经常会出现栈溢出错误,而使用了尾递归优化后就不会发生栈溢出的错误了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// 常规递归的斐波那契函数
function Fibonacci(n) {
if (n <= 1) {
return 1
}
return Fibonacci(n - 1) + Fibonacci(n - 2)
}
Fibonacci(100) // 超时
// 尾递归优化后的斐波那契函数
function Fibonacci2(n, ac1 = 1, ac2 = 1) {
if (n <= 1) {
return ac2
}
return Fibonacci2(n - 1, ac2, ac1 + ac2)
}
s
Fibonacci2(100) // 573147844013817200000
Symbol
Symbol是一个新的原始类型,用来表示一个独一无二的值,可以通过Symbol()函数来创建一个Symbol类型的值,为了加以区分,可以传入一个字符串作为其描述:1
2
3let s1 = Symbol('foo')
let s2 = Symbol('foo')
s1 === s2 // falseSymbol类型无法通过数学运算符进行隐式类型转换,但是可以通过String()显示转成字符串或者通过Boolean()显示转成布尔值:1
2
3
4let s = Symbol('foo')
String(s) // "Symbol('foo')"
s.toString() // "Symbol('foo')"
Boolean(s) // true引入
Symbol最大的初衷其实就是为了让它作为对象的属性名而使用,这样就可以有效避免属性名的冲突了:1
2
3
4
5
6
7let foo = Symbol('foo')
let obj = {
[foo]: 'foo1',
foo: 'foo2',
}
obj[foo] // 'foo1'
obj.foo // 'foo2'Symbol属性的不可枚举性,不会被for...in、for...of、Object.keys()、Object.getOwnPropertyNames()、JSON.stringify()等枚举:1
2
3
4
5
6
7
8
9
10let person = {
name: '布兰',
[Symbol('age')]: 12,
}
for (let x in person) {
console.log(x) // 'name'
}
Object.keys(person) // ['name']
Object.getOwnPropertyNames(person) // ['name']
JSON.stringify(person) // '{"name":"布兰"}'但是可以通过
Object.getOwnPropertySymbols()获取到对象的所有Symbol属性名,返回一个数组:1
2// 基于上面的代码
Object.getOwnPropertySymbols(person) // [Symbol(age)]
静态方法:
Symbol.for()按照描述去全局查找Symbol,找不到则在全局登记一个:1
2
3let s1 = Symbol.for('foo')
let s2 = Symbol.for('foo')
s1 === s2 // trueSymbol.for()的这个全局登记特性,可以用在不同的iframe或service worker中取到同一个值。Symbol.keyFor()根据已经在全局登记的Symbol查找其描述:1
2let s = Symbol.for('foo')
Symbol.keyFor(s) // 'foo'
Symbol 的内置值:
Symbol.hasInstance:指向一个内部方法,当其他对象使用instanceof运算符判断是否为此对象的实例时会调用此方法;Symbol.isConcatSpreadable:指向一个布尔,定义对象用于Array.prototype.concat()时是否可展开;Symbol.species:指向一个构造函数,当实例对象使用自身构造函数时会调用指定的构造函数;Symbol.match:指向一个函数,当实例对象被String.prototype.match()调用时会重新定义 match()的行为;Symbol.replace:指向一个函数,当实例对象被String.prototype.replace()调用时会重新定义replace()的行为;Symbol.search:指向一个函数,当实例对象被String.prototype.search()调用时会重新定义search()的行为;sSymbol.split:指向一个函数,当实例对象被String.prototype.split()调用时会重新定义split()的行为;Symbol.iterator:指向一个默认遍历器方法,当实例对象执行for...of时会调用指定的默认遍历器;Symbol.toPrimitive:指向一个函数,当实例对象被转为原始类型的值时会返回此对象对应的原始类型值;Symbol.toStringTag:指向一个函数,当实例对象被Object.prototype.toString()调用时其返回值会出现在toString()返回的字符串之中表示对象的类型;Symbol.unscopables:指向一个对象,指定使用with时哪些属性会被with环境排除;
Set
Set是一种新的数据结构,类似数组,但是它没有键只有值,且值都是唯一的。可以通过构造函数生成一个新实例,接收一个数组或者可迭代数据结构作为参数:1
2new Set([1, 2, 3]) // Set {1, 2, 3}
new Set('abc') // Set {'a', 'b', 'c'}Set判断两个值是不是相等用的是 sameValueZero 算法,类似于===,唯一的区别是,在Set里NaN之间被认为是相等的:1
2
3
4
5
6let set = new Set()
let a = NaN
let b = NaN
set.add(a)
set.add(b)
set.size // 1相同对象的不同实例也被
Set认为是不相等的:1
2
3
4
5
6let set = new Set()
let a = { a: 1 }
let b = { a: 1 }
set.add(a)
set.add(b)
set.size // 2Set是有顺序的,将按照插入的顺序进行迭代,可以使用for...of迭代:1
2
3
4
5
6let set = new Set([1, 3])
set.add(5)
set.add(7)
for (let x of set) {
console.log(x)
}
Set 实例属性和方法:
Set.prototype.constructor:构造函数,默认就是Set函数;Set.prototype.size:返回Set实例的成员总数;Set.prototype.add(value):添加某个值,返回Set结构本身;Set.prototype.delete(value):删除某个值,返回一个布尔值,表示删除是否成功;Set.prototype.has(value):返回一个布尔值,表示该值是否为 Set 的成员;Set.prototype.clear():清除所有成员,没有返回值;Set.prototype.keys():返回键名的遍历器;Set.prototype.values():返回键值的遍历器;Set.prototype.entries():返回键值对的遍历器;Set.prototype.forEach():使用回调函数遍历每个成员;
1 | let set = new Set([1, 3]) |
Set 应用场景:
数组去重:
1
2;[...new Set([1, 3, 6, 3, 1])] // [1, 3, 6]
Array.from(new Set([1, 3, 6, 3, 1])) // [1, 3, 6]字符串去重:
1
;[...new Set('abcbacd')].join('') // 'abcd'
求两个集合的交集/并集/差集:
1
2
3
4
5
6
7
8
9
10
11let a = new Set([1, 2, 3])
let b = new Set([4, 3, 2])
// 并集
let union = new Set([...a, ...b]) // Set {1, 2, 3, 4}
// 交集
let intersect = new Set([...a].filter((x) => b.has(x))) // set {2, 3}
// (a 相对于 b 的)差集
let difference = new Set([...a].filter((x) => !b.has(x))) // Set {1}遍历修改集合成员的值:
1
2
3
4
5
6
7let set = new Set([1, 2, 3])
// 方法一
let set1 = new Set([...set].map((val) => val * 2)) // Set {2, 3, 6}
// 方法二
let set2 = new Set(Array.from(set, (val) => val * 2)) // Set {2, 4, 6}
WeakSet
WeakSet对象允许将弱保持对象存储在一个集合中:1
2
3
4
5let ws = new WeakSet()
let foo = {}
ws.add(foo) // WeakSet {{}}
ws.has(foo) // true
ws.delete(foo) // WeakSet {}
和 Set 的区别:
WeakSet只能是对象的集合,而不能是任何类型的任意值;WeakSet持弱引用:集合中对象的引用为弱引用。如果没有其他的对WeakSet中对象的引用,那么这些对象会被当成垃圾回收掉。这也意味着WeakSet中没有存储当前对象的列表。正因为这样,WeakSet是不可枚举的,也就没有size属性,没有clear和遍历的方法。
实例方法:
WeakSet.prototype.add(value):添加一个新元素value;WeakSet.prototype.delete(value):从该WeakSet对象中删除value这个元素;WeakSet.prototype.has(value):返回一个布尔值, 表示给定的值value是否存在于这个WeakSet中;
Map
Map是一种类似于Object的这种键值对的数据结构,区别是对象的键只能是字符串或者Symbol,而Map的键可以是任何类型(原始类型、对象或者函数),可以通过Map构造函数创建一个实例,入参是具有Iterator接口且每个成员都是一个双元素数组[key, value]的数据结构:1
2
3
4
5
6
7
8let map1 = new Map()
map1.set({}, 'foo')
let arr = [
['name', '布兰'],
['age', 12],
]
let map2 = new Map(arr)Map中的键和Set里的值一样也必须是唯一的,遵循 sameValueZero 算法,对于同一个键后面插入的会覆盖前面的,1
2
3
4
5let map = new Map()
let foo = { foo: 'foo' }
map.set(foo, 'foo1')
map.set(foo, 'foo2')
map.get(foo) // 'foo2'对于键名同为
NaN以及相同对象而不同实例的处理同Set的值一样:1
2
3
4
5
6
7
8
9
10
11
12
13
14let a = NaN
let b = NaN
let map = new Map()
map.set(a, 'a')
map.set(b, 'b')
map.size // 1
map.get(a) // 'b'
let c = { c: 'c' }
let d = { c: 'c' }
map.set(c, 'c')
map.set(d, 'd')
map.size // 3
map.get(c) // 'c'
实例属性和方法:
Map.prototype.size:返回Map对象的键值对数量;Map.prototype.set(key, value):设置Map对象中键的值。返回该Map对象;Map.prototype.get(key): 返回键对应的值,如果不存在,则返回undefined;Map.prototype.has(key):返回一个布尔值,表示Map实例是否包含键对应的值;Map.prototype.delete(key): 如果Map对象中存在该元素,则移除它并返回true;Map.prototype.clear(): 移除Map对象的所有键/值对;Map.prototype.keys():返回一个新的Iterator对象, 它按插入顺序包含了Map对象中每个元素的键;Map.prototype.values():返回一个新的Iterator对象,它按插入顺序包含了Map对象中每个元素的值;Map.prototype.entries():返回一个新的Iterator对象,它按插入顺序包含了Map对象中每个元素的[key, value]数组;Map.prototype.forEach(callbackFn[, thisArg]):按插入顺序遍历Map;
1 | let map = new Map() |
WeakMap
类似于
Map的结构,但是键必须是对象的弱引用,注意弱引用的是键名而不是键值,因而WeakMap是不能被迭代的;1
2
3
4
5let wm = new WeakMap()
let foo = { name: 'foo' }
wm.set(foo, 'a') // Weak
wm.get(foo) // 'a'
wm.has(foo) // true虽然
wm的键对foo对象有引用,但是丝毫不会阻止foo对象被GC回收。当引用对象foo被垃圾回收之后,wm的foo键值对也会自动移除,所以不用手动删除引用。
实例方法:
WeakMap.prototype.delete(key):移除key的关联对象;WeakMap.prototype.get(key):返回 key 关联对象, 或者 undefined(没有 key 关联对象时);WeakMap.prototype.has(key):根据是否有key关联对象返回一个Boolean值;WeakMap.prototype.set(key, value):在WeakMap中设置一组key关联对象,返回这个WeakMap对象;
Proxy
Proxy用来定义基本操作的的自定义行为,可以理解为当对目标对象target进行某个操作之前会先进行拦截(执行handler里定义的方法),必须要对Proxy实例进行操作才能触发拦截,对目标对象操作是不会拦截的,可以通过如下方式定义一个代理实例1
2
3
4
5
6
7
8
9
10
11let proxy = new Proxy(target, handler)
let instance = new Proxy(
{ name: '布兰' },
{
get(target, propKey, receiver) {
return `hello, ${target.name}`
},
}
)
instance.name // 'hello, 布兰'如果
handle没有设置任何拦截,那么对实例的操作就会转发到目标对象身上:1
2
3
4let target = {}
let proxy = new Proxy(target, {})
proxy.name = '布兰'
target.name // '布兰'目标对象被
Proxy代理的时候,内部的this会指向代理的实例:1
2
3
4
5
6
7
8
9const target = {
m: function () {
console.log(this === proxy)
},
}
const handler = {}
const proxy = new Proxy(target, handler)
target.m() // false
proxy.m() // true
静态方法:
Proxy.revocable()用以定义一个可撤销的Proxy:1
2
3
4
5
6
7
8let target = {}
let handler = {}
let { proxy, revoke } = Proxy.revocable(target, handler)
proxy.foo = 123
proxy.foo // 123
revoke()
proxy.foo // TypeError
handle 对象的方法:
get(target, propKey, receiver):拦截对象属性的读取,比如 proxy.foo 和 proxy[‘foo’]。set(target, propKey, value, receiver):拦截对象属性的设置,比如proxy.foo = v或proxy['foo'] = v,返回一个布尔值。has(target, propKey):拦截propKey in proxy的操作,返回一个布尔值。deleteProperty(target, propKey):拦截delete proxy[propKey]的操作,返回一个布尔值。ownKeys(target):拦截Object.getOwnPropertyNames(proxy)、Object.getOwnPropertySymbols(proxy)、Object.keys(proxy)、for...in循环,返回一个数组。该方法返回目标对象所有自身的属性的属性名,而Object.keys()的返回结果仅包括目标对象自身的可遍历属性。getOwnPropertyDescriptor(target, propKey):拦截Object.getOwnPropertyDescriptor(proxy, propKey),返回属性的描述对象。defineProperty(target, propKey, propDesc):拦截Object.defineProperty(proxy, propKey, propDesc)、Object.defineProperties(proxy, propDescs),返回一个布尔值。preventExtensions(target):拦截Object.preventExtensions(proxy),返回一个布尔值。getPrototypeOf(target):拦截Object.getPrototypeOf(proxy),返回一个对象。isExtensible(target):拦截Object.isExtensible(proxy),返回一个布尔值。setPrototypeOf(target, proto):拦截Object.setPrototypeOf(proxy, proto),返回一个布尔值。如果目标对象是函数,那么还有两种额外操作可以拦截。apply(target, object, args):拦截Proxy实例作为函数调用的操作,比如proxy(...args)、proxy.call(object, ...args)、proxy.apply(...)。construct(target, args):拦截Proxy实例作为构造函数调用的操作,比如new proxy(...args)。
Reflect
Reflect是一个内置的对象,它提供拦截JavaScript操作的方法。这些方法与proxy handlers的方法相同。Reflect不是一个函数对象,因此它是不可构造的。- 设计的目的:
- 将
Object属于语言内部的方法放到Reflect上; - 修改某些
Object方法的返回结果,让其变得更合理; - 让
Object操作变成函数行为; Proxy handles与Reflect方法一一对应,前者用于定义自定义行为,而后者用于恢复默认行为;
- 将
静态方法:
Reflect.apply(target, thisArgument, argumentsList)对一个函数进行调用操作,同时可以传入一个数组作为调用参数。和Function.prototype.apply()功能类似;Reflect.construct(target, argumentsList[, newTarget])对构造函数进行new操作,相当于执行new target(...args);Reflect.defineProperty(target, propertyKey, attributes)和Object.defineProperty()类似。如果设置成功就会返回true;Reflect.deleteProperty(target, propertyKey)作为函数的delete操作符,相当于执行delete target[name];Reflect.get(target, propertyKey[, receiver])获取对象身上某个属性的值,类似于target[name];Reflect.getOwnPropertyDescriptor(target, propertyKey)类似于Object.getOwnPropertyDescriptor()。如果对象中存在该属性,则返回对应的属性描述符, 否则返回undefined;Reflect.getPrototypeOf(target)类似于Object.getPrototypeOf();Reflect.has(target, propertyKey)判断一个对象是否存在某个属性,和in运算符 的功能完全相同;Reflect.isExtensible(target)类似于Object.isExtensible();Reflect.ownKeys(target)返回一个包含所有自身属性(不包含继承属性)的数组。(类似于Object.keys(), 但不会受enumerable影响);Reflect.preventExtensions(target)类似于Object.preventExtensions()。返回一个Boolean;Reflect.set(target, propertyKey, value[, receiver])将值分配给属性的函数。返回一个Boolean,如果更新成功,则返回true;Reflect.setPrototypeOf(target, prototype)设置对象原型的函数. 返回一个Boolean, 如果更新成功,则返回true;
Class
可以用
class关键字来定义一个类,类是对一类具有共同特征的事物的抽象,就比如可以把小狗定义为一个类,小狗有名字会叫也会跳;类是特殊的函数,就像函数定义的时候有函数声明和函数表达式一样,类的定义也有类声明和类表达式,不过类声明不同于函数声明,它是无法提升的;类也有name属性1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// 类声明
class Dog {
constructor(name) {
this.name = name
}
bark() {}
jump() {}
}
Dog.name // 'Dog'
// 类表达式:可以命名(类的 name 属性取类名),也可以不命名(类的 name 属性取变量名)
let Animal2 = class {
// xxx
}
Animal2.name // 'Animal2'JS中的类建立在原型的基础上(通过函数来模拟类,其实类就是构造函数的语法糖),和ES5中构造函数类似,但是也有区别,比如类的内部方法是不可被迭代的:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class Dog {
constructor() {}
bark() {}
jump() {}
}
Object.keys(Dog.prototype) // []
// 类似于
function Dog2() {}
Dog2.prototype = {
constructor() {},
bark() {},
jump() {},
}
Object.keys(Dog2.prototype) // ['constructor', 'bark', 'jump']基于原型给类添加新方法:
1
2
3Object.assign(Dog.prototype, {
wag() {}, // 摇尾巴
})类声明和类表达式的主体都执行在严格模式下。比如,构造函数,静态方法,原型方法,
getter和setter都在严格模式下执行。类内部的
this默认指向类实例,所以如果直接调用原型方法或者静态方法会导致this指向运行时的环境,而类内部是严格模式,所以此时的this会是undefined:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class Dog {
constructor(name) {
this.name = name
}
bark() {
console.log(`${this.name} is bark.`)
}
static jump() {
console.log(`${this.name} is jump.`)
}
}
let dog = new Dog('大黄')
let { bark } = dog
let { jump } = Dog
bark() // TypeError: Cannot read property 'name' of undefined
jump() // TypeError: Cannot read property 'name' of undefined
方法和关键字:
constructor方法是类的默认方法,通过new关键字生成实例的时候,会自动调用;一个类必须有constructor方法,如果没有显示定义,则会自动添加一个空的;constructor默认会返回实例对象:
1 | class Point {} |
- 通过
get和set关键字拦截某个属性的读写操作:
1 | class Dog { |
用
static关键字给类定义静态方法,静态方法不会存在类的原型上,所以不能通过类实例调用,只能通过类名来调用,静态方法和原型方法可以同名:1
2
3
4
5
6
7
8
9
10
11
12
13class Dog {
bark() {}
jump() {
console.log('原型方法')
}
static jump() {
console.log('静态方法')
}
}
Object.getOwnPropertyNames(Dog.prototype) // ['constructor', 'bark', 'jump']
Dog.jump() // '静态方法'
let dog = new Dog()
dog.jump() // '原型方法'公有字段和私有字段:
静态公有字段和静态方法一样只能通过类名调用;私有属性和私有方法只能在类的内部调用,外部调用将报错:
1
2
3
4
5
6
7
8
9
10
11
12class Dog {
age = 12 // 公有字段
static sex = 'male' // 静态公有字段
#secret = '我是人类的好朋友' // 私有字段
#getSecret() {
// 私有方法
return this.#secret
}
}
Dog.sex // 'male'
let dog = new Dog()
dog.#getSecret() // SyntaxError公共和私有字段声明是 JavaScript 标准委员会 TC39 提出的实验性功能(第 3 阶段)。浏览器中的支持是有限的,但是可以通过 Babel 等系统构建后使用此功能。
new.target属性允许你检测函数、构造方法或者类是否是通过new运算符被调用的。在通过new运算符被初始化的函数或构造方法中,new.target返回一个指向构造方法或函数的引用。在普通的函数调用中,new.target的值是undefined,子类继承父类的时候会返回子类:1
2
3
4
5
6
7
8
9
10
11
12class Dog {
constructor() {
console.log(new.target.name)
}
}
function fn() {
if (!new.target) return 'new target is undefined'
console.log('fn is called by new')
}
let dog = new Dog() // 'Dog'
fn() // 'new target is undefined'
new fn() // 'fn is called by new'
类的继承:
类可以通过
extends关键字实现继承,如果子类显示的定义了constructor则必须在内部调用super()方法,内部的this指向当前子类:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class Animal {
constructor(name) {
this.name = name
}
run() {
console.log(`${this.name} is running.`)
}
}
class Dog extends Animal {
constructor(name) {
super(name) // 必须调用
this.name = name
}
bark() {
console.log(`${this.name} is barking.`)
}
}
let dog = new Dog('大黄')
dog.run() // '大黄 is running.'通过
super()调用父类的构造函数或者通过super调用父类的原型方法;另外也可以在子类的静态方法里通过super调用父类的静态方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// 基于上面的代码改造
class Dog extends Animal{
constructor(name){
super(name) // 调用父类构造函数
this.name = name
}
bark() {
super.run() // 调用父类原型方法
console.log(`${this.name} is barking.`)
}
}
let dog = new Dog()
dog.bark()s
// '大黄 is running.'
// '大黄 is barking.'子类的
__proto__属性,表示构造函数的继承,总是指向父类;子类prototype属性的__proto__属性,表示方法的继承,总是指向父类的 prototype 属性:1
2
3
4
5class Animal {}
class Dog extends Animal {}
Dog.__proto__ === Animal // true
Dog.prototype.__proto__ === Animal.prototype // true子类原型的原型指向父类的原型:
1
2
3
4// 基于上面的代码
let animal = new Animal()
let dog = new Dog()
dog.__proto__.__proto__ === animal.__proto__ // true使用
extends还可以实现继承原生的构造函数,如下这些构造函数都可以被继承:String()Number()Boolean()Array()Object()Function()Date()RegExp()Error()
1
2
3
4
5
6
7
8
9
10
11
12
13class MyString extends String {
constructor(name) {
super(name)
this.name = name
}
welcome() {
return `hello ${this.name}`
}
}
let ms = new MyString('布兰')
ms.welcome() // 'hello 布兰'
ms.length // 2
ms.indexOf('兰') // 1
Module
浏览器传统加载模块方式:
1
2
3
4
5
6
7
8// 同步加载
<script src="test.js"></script>
// defer异步加载:顺序执行,文档解析完成后执行;
<script src="test.js" defer></script>
// async异步加载:乱序加载,下载完就执行。
<script src="test.js" async></script>浏览器现在可以按照模块(加上
type="module")来加载脚本,默认将按照defer的方式异步加载;ES6的模块加载依赖于import和export这 2 个命令;模块内部自动采用严格模式:1
2// 模块加载
<script type="module" src="test.js"></script>export用于输出模块的对外接口,一个模块内只能允许一个export default存在,以下是几种输出模块接口的写法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// person.js
// 写法一:单独导出
export const name = '布兰'
export const age = 12
// 写法二:按需导出
const name = '布兰',
age = 12
export { name, age }
// 写法三:重命名后导出
const name = '布兰',
age = 12
export { name as name1, age as age1 }
// 写法四:默认导出
const name = '布兰'
export default nameimport用于输入其他模块的接口:1
2
3
4
5
6
7
8
9
10
11
12
13
14// 按需导入
import { name, age } './person.js'
// 导入后重命名
import { name1 as name, age1 as age } from './person.js'
// 默认导入
import person from './person.js'
// 整体导入
import * as person from './person.js'
// 混合导入
import _, { each } from 'lodash'import导入的细节:- 导入的变量名必须与导出模块的名字一致,可以使用
as进行重命名; - 导入的变量都是只读的,不能改写;
import命令具有提升效果,会提升到整个模块的头部,首先执行;import是编译时导入,所以不能将其写到代码块(比如if判断块里)或者函数内部;import会执行所加载的模块的代码,如果重复导入同一个模块则只会执行一次模块;
- 导入的变量名必须与导出模块的名字一致,可以使用
import和export的复合写法:export和import语句可以结合在一起写成一行,相当于是在当前模块直接转发外部模块的接口,复合写法也支持用as重命名。以下例子中需要在hub.js模块中转发person.js的接口:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// person.js
const name = '布兰', age = 12
export { name, age }
// 按需转发接口(中转模块:hub.js)
export { name, age } from './person.js'
// 相当于
import { name, age } from './person.js'
export { name, age }
// person.js
const name = '布兰', age = 12
export default { name, age }
// 转发默认接口(中转模块:hub.js)
export { default } from './person.js'
// 相当于
import person from './person.js'
export default personES6模块和CommonJS模块的差异:CommonJS模块输出的是一个值的拷贝(一旦输出一个值,模块内部的变化就影响不到这个值),ES6模块输出的是值的引用(是动态引用且不会缓存值,模块里的变量绑定其所在的模块,等到脚本真正执行时,再根据这个只读引用到被加载的那个模块里去取值);CommonJS模块是运行时加载,ES6模块是编译时输出接口;CommonJS模块的require()是同步加载模块,ES6模块的import命令是异步加载,有一个独立的模块依赖的解析阶段;
Iterator 和 for…of
Iterator迭代器协议,为各种数据结构提供了一种统一按照某种顺序进行访问的机制。通常部署在一个可迭代数据结构内部或其原型上。一个对象要能够成为迭代器,它必须有一个next()方法,每次执行next()方法会返回一个对象,这个对象包含了一个done属性(是个布尔值,true表示可以继续下次迭代)和一个value属性(每次迭代的值):1
2
3
4
5
6
7
8
9
10
11
12
13
14// 生成一个迭代器
let makeIterator = (arr) => {
let index = 0
return {
next() {
return index < arr.length
? {
value: arr[index++],
done: false,
}
: { done: true }
},
}
}iterable可迭代数据结构:内部或者原型上必须有一个Symbol.iterator属性(如果是异步的则是Symbol.asyncIterator),这个属性是一个函数,执行后会生成一个迭代器:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17let obj = {
[Symbol.iterator]() {
return {
index: 0,
next() {
if (this.index < 3) {
return { value: this.index++, done: false }
} else {
return { done: true }
}
},
}
},
}
for (let x of obj) {
console.log(x) // 0 1 2
}内置的一些可迭代数据结构有:
String、Array、TypedArray、Map和Set、arguments、NodeList:1
2
3
4
5let si = 'hi'[Symbol.iterator]()
si // StringIterator
si.next() // {value: 'h', done: false}
si.next() // {value: 'i', done: false}
si.next() // {value: undefined, done: true}for...of:用于遍历可迭代数据结构:- 遍历字符串:
for...in获取索引,for...of获取值; - 遍历数组:
for...in获取索引,for...of获取值; - 遍历对象:
for...in获取键,for...of需自行部署[Symbol.iterator]接口; - 遍历
Set:for...of获取值,for (const v of set); - 遍历
Map:for...of获取键值对,for (const [k, v] of map); - 遍历类数组:包含
length的对象、arguments对象、NodeList对象(无Iterator接口的类数组可用Array.from()转换);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24// 迭代字符串
for (let x of 'abc') {
console.log(x) // 'a' 'b' 'c'
}
// 迭代数组
for (let x of ['a', 'b', 'c']) {
console.log(x) // 'a' 'b' 'c'
}
// 遍历 Set
let set = new Set(['a', 'b', 'c'])
for (let x of set) {
console.log(x) // 'a' 'b' 'c'
}
// 遍历 Map
let map = new Map([
['name', '布兰'],
['age', 12],
])
for (let [key, value] of map) {
console.log(key + ': ' + value) // 'name: 布兰' 'age: 12'
}- 遍历字符串:
for...of和for...in对比共同点:能够通过
break、continue和return跳出循环;
不同点:for...in的特点:只能遍历键,会遍历原型上属性,遍历无顺序,适合于对象的遍历;for...of的特点:能够遍历值(某些数据结构能遍历键和值,比如Map),不会遍历原型上的键值,遍历顺序为数据的添加顺序,适用于遍历可迭代数据结构;
Promise
Promise 这块知识可以直接看我之前写的一篇文章:深入理解 Promise 非常完整。
Generator
function*会定义一个生成器函数,调用生成器函数不会立即执行,而是会返回一个Generator对象,这个对象是符合可迭代协议和迭代器协议的,换句话说这个Generator是可以被迭代的。生成器函数内部通过
yield来控制暂停,而next()将把它恢复执行,它的运行逻辑是如下这样的:- 遇到
yield表达式,就暂停执行后面的操作,并将紧跟在yield后面的那个表达式的值作为返回的对象的value属性值; - 下一次调用
next方法时,再继续往下执行,直到遇到下一个yield表达式; - 如果没有再遇到新的
yield表达式,就一直运行到函数结束,直到return语句为止,并将return语句后面的表达式的值,作为返回的对象的value属性值; - 如果该函数没有
return语句,则返回的对象的value属性值为undefined;
1
2
3
4
5
6
7
8
9function* gen() {
yield 'hello'
yield 'world'
return 'end'
}
let g = gen()
g.next() // {value: 'hello', done: false}
g.next() // {value: 'world', done: false}
g.next() // {value: 'end', done: true}- 遇到
在生成器函数内部可以使用
yield*表达式委托给另一个Generator或可迭代对象,比如数组、字符串等;yield*表达式本身的值是当迭代器关闭时返回的值(即done为true时):1
2
3
4
5
6
7
8
9
10
11
12function* inner() {
yield* [1, 2]
return 'foo'
}
function* gen() {
let result = yield* inner()
console.log(result)
}
let g = gen()
g.next()
g.next()
g.next()
实例方法:
Generator.prototype.next():返回一个包含属性done和value的对象。该方法也可以通过接受一个参数用以向生成器传值。如果传入了参数,那么这个参数会传给上一条执行的yield语句左边的变量:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15function* f() {
let a = yield 12
console.log(a)
let b = yield a
console.log(b)
}
let g = f()
console.log(g.next('a'))
console.log(g.next('b'))
console.log(g.next('c'))
// {value: 12, done: false}
// 'b'
// {value: 'b', done: false}
// 'c'
// {value: undefined, done: true}Generator.prototype.throw():用来向生成器抛出异常,如果内部捕获了则会恢复生成器的执行(即执行下一条yield表达式),并且返回带有done及value两个属性的对象:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17function* gen() {
try {
yield 'a'
} catch(e) {
console.log(e)
}
yiele 'b'
yield 'c'
}
let g = gen()
g.next()
g.throw('error a')
g.next()
// {value: "a", done: false}
// 'error a'
// {value: "b", done: false}
// {value: "c", done: false}如果内部没有捕获异常,将中断内部代码的继续执行(类似
throw抛出的异常,如果没有捕获,则后面的代码将不会执行),此时异常会抛到外部,可以被外部的try...catch块捕获,此时如果再执行一次next(),会返回一个值为done属性为true的对象:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16function* gen() {
yield 'a'
yield 'b'
yield 'c'
}
let g = gen()
g.next()
try {
g.throw('error a')
} catch (e) {
console.log(e)
}
g.next()
// {value: "a", done: false}
// 'error a'
// {value: undefined, done: true}Generator.prototype.return():返回给定的值并结束生成器:1
2
3
4
5
6
7
8
9function* gen() {
yield 1
yield 2
yield 3
}
let g = gen()
g.next() // { value: 1, done: false }
g.return('foo') // { value: "foo", done: true }
g.next() // { value: undefined, done: true }
应用:
将异步操作同步化,比如同时有多个请求,多个请求之间是有顺序的,只能等前面的请求完成了才请求后面的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17function* main() {
let res1 = yield request('a')
console.log(res1)
let res2 = yield request('b')
console.log(res2)
let res3 = yield request('c')
console.log(res3)
}
function request(url) {
setTimeout(function () {
// 模拟异步请求
it.next(url)
}, 300)
}
let it = main()
it.next()
// 'a' 'b' 'c'给对象部署
Iterator接口:1
2
3
4
5
6
7
8
9
10
11
12
13function* iterEntries(obj) {
let keys = Object.keys(obj)
for (let i = 0; i < keys.length; i++) {
let key = keys[i]
yield [key, obj[key]]
}
}
let obj = { foo: 3, bar: 7 }
for (let [key, value] of iterEntries(myObj)) {
console.log(key, value)
}
// 'foo' 3
// 'bar' 7
ES2016

Array.prototype.includes
判断一个数组是否包含某个元素,之前一般是这么做的:
1 | if (arr.indexOf(el) >= 0) { |
而现在你可以这么做了:
1 | if (arr.includes(el)) { |
indexOf 会返回找到元素在数组中的索引位置,判断的逻辑是是否严格相等,所以他在遇到 NaN 的时候不能正确返回索引,但是 includes 解决了这个问题:
1 | ;[1, NaN, 3] |
求幂运算符(**)
x ** y 是求 x 的 y 次幂,和 Math.pow(x, y) 功能一致:
1 | // x ** y |
x **= y 表示求 x 的 y 次幂,并且把结果赋值给 x:
1 | // x **= y |
ES2017
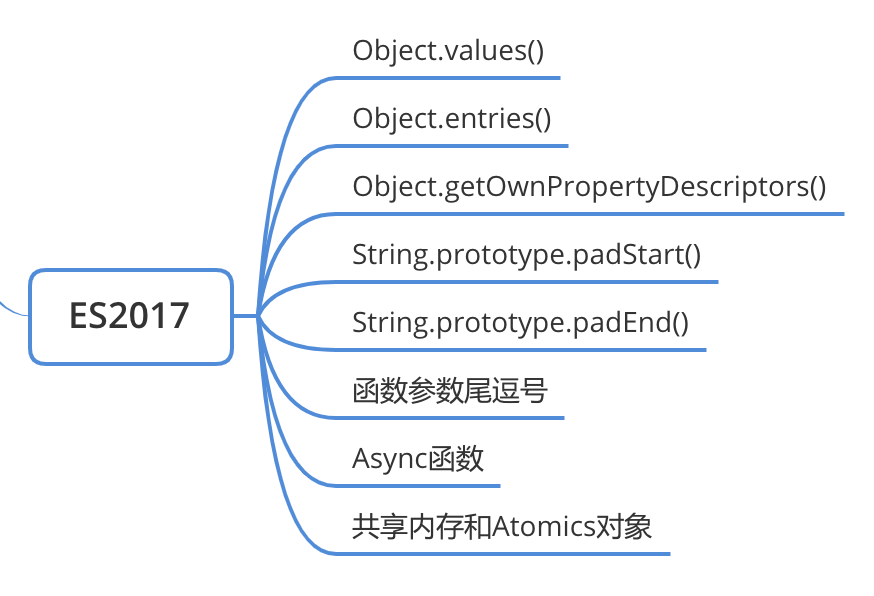
Object.values()
返回一个由对象自身所有可遍历属性的属性值组成的数组:
1 | const person = { name: '布兰' } |
Object.entries()
返回一个由对象自身所有可遍历属性的键值对组成的数组:
1 | const person = { name: '布兰', age: 12 } |
利用这个方法可以很好的将对象转成正在的 Map 结构:
1 | const person = { name: '布兰', age: 12 } |
Object.getOwnPropertyDescriptors()
Object.getOwnPropertyDescriptor() 会返回指定对象某个自身属性的的描述对象,而 Object.getOwnPropertyDescriptors() 则是返回指定对象自身所有属性的描述对象:
1 | const person = { name: '布兰', age: 12 } |
配合 Object.create() 可以实现浅克隆:
1 | const shallowClone = (obj) => |
String.prototype.padStart()
str.padStart(length [, padStr]) 会返回一个新字符串,该字符串将从 str 字符串的左侧开始填充某个字符串 padStr(非必填,如果不是字符串则会转成字符串, 传入 undefined 和不传这个参数效果一致)直到达到指定位数 length 为止:
1 | 'abc'.padStart(5, 2) // '22abc' |
String.prototype.padEnd()
规则和 padStart 类似,但是是从字符串右侧开始填充:
1 | 'abc'.padEnd(5, 2) // 'abc22' |
函数参数尾逗号
允许函数在定义和调用的时候时候最后一个参数后加上逗号:
1 | function init(param1, param2) {} |
Async 函数
使用
async可以声明一个async函数,结合await可以用一种很简介的方法写成基于Promise的异步行为,而不需要刻意的链式调用。await表达式会暂停整个async函数的执行进程并出让其控制权,只有当其等待的基于Promise的异步操作被兑现或被拒绝之后才会恢复进程。async函数有如下几种定义形式:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// 函数声明
async function foo() {}
// 函数表达式
let foo = async function() {}
// 箭头函数
let foo = async () => {}
// 对象方法
lef obj = {
async foo() {}
}
// 类方法
class Dog {
async bark() {}
}async函数一定会返回一个Promise对象,所以它可以使用then添加处理函数。如果一个async函数的返回值看起来不是Promise,那么它将会被隐式地包装在一个Promise中:1
2
3
4
5
6async function foo() {
return 'a'
}
foo().then((res) => {
console.log(res) // 'a'
})内部如果发生错误,或者显示抛出错误,那么
async函数会返回一个rejected状态的Promsie:1
2
3
4
5
6async function foo() {
throw new Error('error')
}
foo().catch((err) => {
console.log(err) // Error: error
})返回的
Promise对象必须等到内部所有await命令Promise对象执行完才会发生状态改变,除非遇到return语句或抛出错误;任何一个await命令返回的Promise对象变为rejected状态,整个Async函数都会中断后续执行:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16async function fn() {
let a = await Promise.resolve('success')
console.log('a_' + a)
let b = await Promise.reject('fail')
console.log('b_' + b) // 不会执行
}
fn().then(
(res) => {
console.log(res) // 不会执行
},
(err) => {
console.log(err)
}
)
// 'a_success'
// 'fail'所以为了保证
async里的异步操作都能完成,我们需要将他们放到try...catch()块里或者在await返回的Promise后跟一个catch处理函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20async function fn() {
try {
let a = await Promise.reject('a fail')
console.log('a_' + a) // 不会执行
} catch (e) {
console.log(e) // 'a fail'
}
let b = await Promise.reject('b fail').catch((e) => {
console.log(e) // 'b fail'
})
console.log('b_' + b) // 'bundefined'
}
fn().then(
(res) => {
console.log(res) // undefined
},
(err) => {
console.log(err) // 不会执行
}
)如果
async函数里的多个异步操作之间没有依赖关系,建议将他们写到一起减少执行时间:1
2
3
4
5
6
7
8// 写法一
let [foo, bar] = await Promise.all([getFoo(), getBar()])
// 写法二
let fooPromise = getFoo()
let barPromise = getBar()
let foo = await fooPromise
let bar = await barPromiseawait命令只能用在async函数之中,如果用在普通函数,就会报错。
共享内存和 Atomics 对象
ES2018
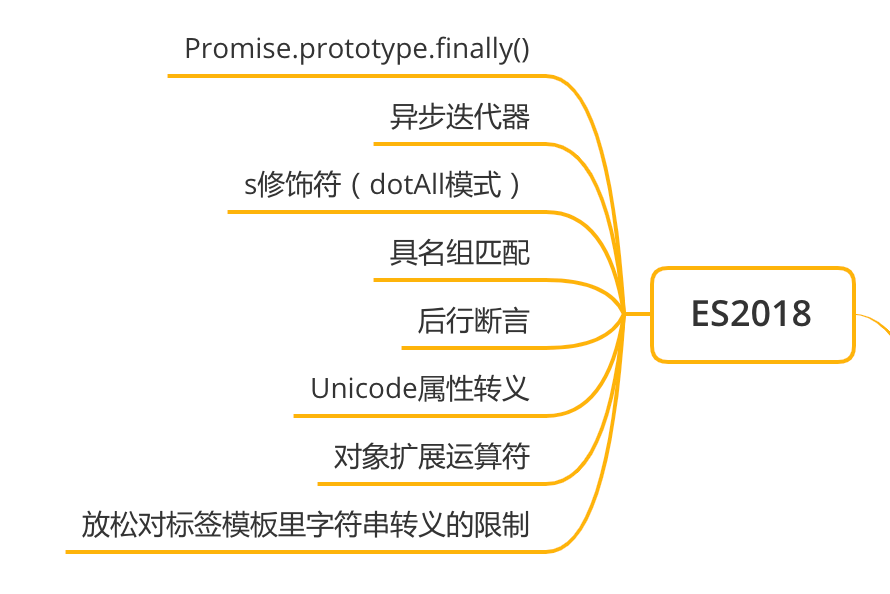
Promise.prototype.finally()
Promise.prototype.finally() 用于给 Promise 对象添加 onFinally 函数,这个函数主要是做一些清理的工作,只有状态变化的时候才会执行该 onFinally 函数。
1 | function onFinally() { |
finally() 会生成一个 Promise 新实例,finally 一般会原样后传父 Promise,无论父级实例是什么状态:
1 | let p1 = new Promise(() => {}) |
上面说的是一般,但是也有特殊情况,比如 finally 里返回了一个非 fulfilled 的 Promise 或者抛出了异常的时候,则会返回对应状态的新实例:
1 | let p1 = new Promise((resolve, reject) => { |
参考:深入理解 Promise
异步迭代器
想要了解异步迭代器最好的方式就是和同步迭代器进行对比。我们知道可迭代数据的内部都是有一个 Symbol.iterator 属性,它是一个函数,执行后会返回一个迭代器对象,这个迭代器对象有一个 next() 方法可以对数据进行迭代,next() 执行后会返回一个对象,包含了当前迭代值 value 和 标识是否完成迭代的 done 属性:
1 | let iterator = [1, 2][Symbol.iterator]() |
上面这里的 next() 执行的是同步操作,所以这个是同步迭代器,但是如果 next() 里需要执行异步操作,那就需要异步迭代了,可异步迭代数据的内部有一个 Symbol.asyncIterator 属性,基于此我们来实现一个异步迭代器:
1 | class Emitter { |
异步迭代器的 next() 会进行异步的操作,通常是返回一个 Promise,所以需要对应的处理函数去处理结果:
1 | let emitter = new Emitter([1, 2, 3]) |
另外也可以使用 for await...of 来迭代异步可迭代数据:
1 | let asyncIterable = new Emitter([1, 2, 3]) |
另外还可以通过异步生成器来创建异步迭代器:
1 | class Emitter { |
参考:
s 修饰符(dotAll 模式)
正则表达式新增了一个 s 修饰符,使得 . 可以匹配任意单个字符:
1 | ;/foo.bar/.test('foo\nbar') / // false |
上面这又被称为 dotAll 模式,表示点(dot)代表一切字符。所以,正则表达式还引入了一个 dotAll 属性,返回一个布尔值,表示该正则表达式是否处在 dotAll 模式:
1 | ;/foo.bar/s.dotAll // true |
具名组匹配
正则表达式可以使用捕获组来匹配字符串,但是想要获取某个组的结果只能通过对应的索引来获取:
1 | let re = /(\d{4})-(\d{2})-(\d{2})/ |
而现在我们可以通过给捕获组 (?<name>...) 加上名字 name ,通过名字来获取对应组的结果:
1 | let re = /(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/ |
配合解构赋值可以写出非常精简的代码:
1 | let { |
具名组也可以通过传递给 String.prototype.replace 的替换值中进行引用。如果该值为字符串,则可以使用 $<name> 获取到对应组的结果:
1 | let re = /(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/ |
参考:proposal-regexp-named-groups
后行断言
后行断言: (?<=y)x,x 只有在 y 后面才能匹配:
1 | ;/(?<=\$)\d+/.exec('I have $100.') // ['100'] |
后行否定断言: (?<!y)x,x 只有不在 y 后面才能匹配:
1 | ;/(?<!\$)\d+/.exec('I have $100.') // ['00'] |
Unicode 属性转义
允许正则表达式匹配符合 Unicode 某种属性的所有字符,\p{...} 是匹配包含,\P{...} 是匹配不包含的字符,且必须搭配 /u 修饰符才会生效:
1 | /\p{Emoji}+/u.exec('😁😭笑死我了🤣😂不行了') // ['😁😭'] |
这里可以查询到更多的 Unicode 的属性 Full_Properties
对象扩展运算符
对象的扩展运算符可以用到解构赋值上,且只能应用到最后一个变量上:
1 | let { x, ...y } = { x: 1, a: 2, b: 3 } |
对象扩展运算符不能解构原型上的属性:
1 | let obj = { x: 1 } |
应用一:可以实现浅拷贝,但是不会拷贝原始属性:
1 | let person = Object.create({ name: '布兰' }) |
应用二:合并两个对象:
1 | let ab = { ...a, ...b } |
应用三:重写对象属性
1 | let aWithOverrides = { ...a, x: 1, y: 2 } |
应用四:给新对象设置默认值
1 | let aWithDefaults = { x: 1, y: 2, ...a } |
应用五:利用扩展运算符的解构赋值可以扩展函数参数:
1 | function baseFunction({ a, b }) {} |
参考:
放松对标签模板里字符串转义的限制
ES2019
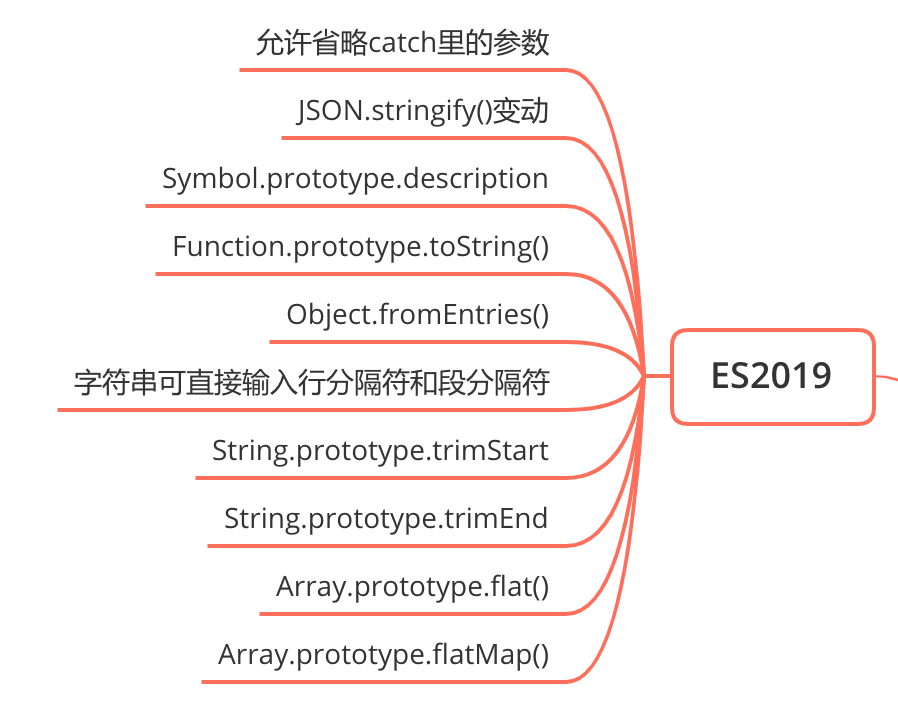
允许省略 catch 里的参数
异常被捕获的时候如果不需要做操作,甚至可以省略 catch(err) 里的参数和圆括号:
1 | try { |
JSON.stringify()变动
UTF-8 标准规定,0xD800 到 0xDFFF 之间的码点,不能单独使用,必须配对使用。
所以 JSON.stringify() 对单个码点进行操作,如果码点符合 UTF-8 标准,则会返回对应的字符,否则会返回对应的码点:
1 | JSON.stringify('\u{1f600}') // ""😀"" |
Symbol.prototype.description
Symbol 实例新增了一个描述属性 description:
1 | let symbol = Symbol('foo') |
Function.prototype.toString()
函数的 toString() 会原样输出函数定义时候的样子,不会省略注释和空格。
Object.fromEntries()
Object.fromEntries() 方法是 Object.entries() 的逆操作,用于将一个键值对数组转为对象:
1 | let person = { name: '布兰', age: 12 } |
常用可迭代数据结构之间的装换:
1 | let person = { name: '布兰', age: 12 } |
字符串可直接输入行分隔符和段分隔符
JavaScript 规定有 5 个字符,不能在字符串里面直接使用,只能使用转义形式。
U+005C:反斜杠(reverse solidus)U+000D:回车(carriage return)U+2028:行分隔符(line separator)U+2029:段分隔符(paragraph separator)U+000A:换行符(line feed)
但是由于 JSON 允许字符串里可以使用 U+2028 和 U+2029,所以使得 JSON.parse() 去解析字符串的时候可能会报错,所以 ES2019 允许模板字符串里可以直接这两个字符:
1 | JSON.parse('"\u2028"') // "" |
String.prototype.trimStart
消除字符串头部空格,返回一个新字符串;浏览器还额外增加了它的别名函数 trimLeft():
1 | let str = ' hello world ' |
String.prototype.trimEnd
消除字符串尾部空格,返回一个新字符串;浏览器还额外增加了它的别名函数 trimRight():
1 | let str = ' hello world ' |
Array.prototype.flat()
arr.flat(depth) 按照 depth (不传值的话默认是 1)深度拍平一个数组,并且将结果以新数组形式返回:
1 | // depth 默认是 1 |
用 reduce 实现拍平一层数组:
1 | const arr = [1, 2, [3, 4]] |
参考:flat
Array.prototype.flatMap()
flatMap(callback) 使用映射函数 callback 映射每个元素,callback 每次的返回值组成一个数组,并且将这个数组执行类似 arr.flat(1) 的操作进行拍平一层后最后返回结果:
1 | const arr1 = [1, 2, 3, 4] |
参考:flatMap
ES2020
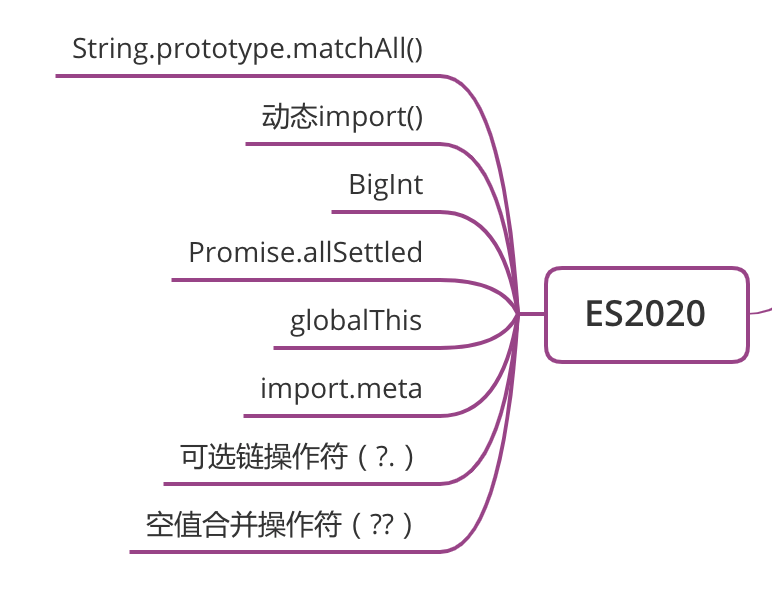
String.prototype.matchAll()
String.prototype.matchAll() 方法,可以一次性取出所有匹配。不过,它返回的是一个 RegExpStringIterator 迭代器同是也是一个可迭代的数据结构,所以可以通过 for...of 进行迭代:
1 | let str = 'test1test2' |
注意当使用 matchAll(regexp) 的时候,正则表达式必须加上 /g 修饰符。
也可以将这个可迭代数据转成数组形式:
1 | // 方法一 |
动态 import()
标准用法的 import 导入的模块是静态的,会使所有被导入的模块,在加载时就被编译(无法做到按需编译,降低首页加载速度)。有些场景中,你可能希望根据条件导入模块或者按需导入模块,这时你可以使用动态导入代替静态导入。
比如按需加载一个模块可以这样:
1 | if (xxx) { |
import() 是异步导入的,结果会返回一个 Promise:
1 | import('/module.js').then((module) => { |
动态 import() 的应用场景挺多的,比如 Vue 中的路由懒加载就是使用的动态导入组件。另外由于动态性不便于静态分析工具和 tree-shaking 工作,所以不能滥用。
BigInt
BigInt 是一种内置对象,它提供了一种方法来表示大于 $2^{53}$ - 1 的整数。这原本是 Javascript 中可以用 Number 表示的最大数字。BigInt 可以表示任意大的整数。
为了区分 Number,定义一个 BigInt 需要在整数后面加上一个 n,或者用函数直接定义:
1 | const num1 = 10n |
Number 和 BigInt 之间能进行比较,但他们之间是宽松相等;且由于他们表示的是不同类型的数字,所以不能直接进行四则运算:
1 | 10n == 10 // true |
Promise.allSettled
Promise.allSettled(iterable) 当所有的实例都已经 settled,即状态变化过了,那么将返回一个新实例,该新实例的内部值是由所有实例的值和状态组合成的数组,数组的每项是由每个实例的状态和内部值组成的对象。
1 | function init() { |
只要所有实例中包含一个 pending 状态的实例,那么 Promise.allSettled() 的结果为返回一个这样 Promise {<pending>} 的实例。
globalThis
在以前,从不同的 JavaScript 环境中获取全局对象需要不同的语句。在 Web 中,可以通过 window、self 或者 frames 取到全局对象,但是在 Web Workers 中,只有 self 可以。在 Node.js 中,它们都无法获取,必须使用 global。
而现在只需要使用 globalThis 即可获取到顶层对象,而不用担心环境问题。
1 | // 在浏览器中 |
import.meta
import.meta 是一个给 JavaScript 模块暴露特定上下文的元数据属性的对象。它包含了这个模块的信息,比如说这个模块的 URL,import.meta 必须在一个模块里使用:
1 | // 没有声明 type="module",就使用 import.meta 会报错 |
如果需要在配置了 Webpack 的项目,比如 Vue 里使用 import.meta 需要加一个包且配置一下参数,否则项目编译阶段会报错。
包配置详情参考:@open-wc/webpack-import-meta-loader
比如我用的是 4.x 版本的 vue-cli,那我需要在 vue.config.js 里配置:
1 | module.exports = { |
可选链操作符(?.)
通常我们获取一个深层对象的属性会需要写很多判断或者使用逻辑与 && 操作符,因为对象的某个属性如果为 null 或者 undefined 就有可能报错:
1 | let obj = { |
?. 操作符允许读取位于连接对象链深处的属性的值,而不必明确验证链中的每个引用是否有效。如果某个属性为 null 或者 undefined 则结果直接为 undefined。有了可选链操作符就可以使得表达式更加简明了,对于上面例子用可选链操作符可以这么写:
1 | let name3 = obj?.first?.second |
空值合并操作符(??)
对于逻辑或 || 运算符,当对运算符左侧的操作数进行装换为 Boolean 值的时候,如果为 true,则取左边的操作数为结果,否则取右边的操作数为结果:
1 | let name = '' || '布兰' |
我们都知道 ''、0、null、undefined、false、NaN 等转成 Boolean 值的时候都是 false,所以都会取右边的操作数。这个时候如果要给变量设置默认值,如果遇到本身值就可能是 '' 或 0 的情况那就会出错了,会被错误的设置为默认值了。
而 ?? 操作符就是为了解决这个问题而出现的,x ?? y 只有左侧的操作数为 null 或 undefined 的时候才取右侧操作数,否则取左侧操作数:
1 | let num = 0 ?? 1 |
ES2021

如下这几个提案已经确定了会在 2021 年发布,所以把他们归到 ES2021 中。
String.prototype.replaceAll
之前需要替换一个字符串里的全部匹配字符可以这样做:
1 | const queryString = 'q=query+string+parameters' |
而现在只需要这么做:
1 | const withSpace3 = queryString.replaceAll('+', ' ') |
replaceAll 的第一个参数可以是字符串也可以是正则表达式,当是正则表达式的时候,必须加上全局修饰符 /g,否则报错。
Promise.any()
Promsie.any() 和 Promise.all() 一样接受一个可迭代的对象,然后依据不同的入参会返回不同的新实例:
传一个空的可迭代对象或者可迭代对象所有
Promise都是rejected状态的,则会抛出一个AggregateError类型的错误,同时返回一个rejected状态的新实例:1
2
3
4let p1 = Promise.any([])
let p2.catch(err => {})
setTimeout(console.log, 0, p1)
// Promise {<rejected>: AggregateError: All promises were rejected}只要可迭代对象里包含任何一个
fulfilled状态的Promise,则会返回第一个fulfilled的实例,并且以它的值作为新实例的值:1
2
3
4
5
6
7
8let p = Promise.any([
1,
Promise.reject(2),
new Promise((resolve, reject) => {}),
Promise.resolve(3),
])
setTimeout(console.log, 0, p)
// Promise {<fulfilled>: 1}其他情况下,都会返回一个
pending状态的实例:1
2
3
4
5
6
7let p = Promise.any([
Promise.reject(2),
Promise.reject(3),
new Promise((resolve, reject) => {}),
])
setTimeout(console.log, 0, p)
// Promise {<pending>: undefined}
WeakRef
我们知道一个普通的引用(默认是强引用)会将与之对应的对象保存在内存中。只有当该对象没有任何的强引用时,JavaScript 引擎 GC 才会销毁该对象并且回收该对象所占的内存空间。
WeakRef 对象允许你保留对另一个对象的弱引用,而不会阻止被弱引用的对象被 GC 回收。WeakRef 的实例方法 deref() 可以返回当前实例的 WeakRef 对象所绑定的 target 对象,如果该 target 对象已被 GC 回收则返回 undefined:
1 | let person = { name: '布兰', age: 12 } |
正确使用 WeakRef 对象需要仔细的考虑,最好尽量避免使用。这里面有诸多原因,比如:GC 在一个 JavaScript 引擎中的行为有可能在另一个 JavaScript 引擎中的行为大相径庭,或者甚至在同一类引擎,不同版本中 GC 的行为都有可能有较大的差距。GC 目前还是 JavaScript 引擎实现者不断改进和改进解决方案的一个难题。
参考:
逻辑赋值符
逻辑赋值符包含 3 个:
x &&= y:逻辑与赋值符,相当于x && (x = y)x ||= y:逻辑或赋值符,相当于x || (x = y)x ??= y:逻辑空赋值符,相当于x ?? (x = y)
看如下示例,加深理解:
1 | let x = 0 |
数值分隔符(_)
对于下面一串数字,你一眼看上去不确定它到底是多少吧?
1 | const num = 1000000000 |
那现在呢?是不是可以很清楚的看出来它是 10 亿:
1 | const num = 1_000_000_000 |
数值分隔符(_)的作用就是为了让数值的可读性更强。除了能用于十进制,还可以用于二级制,十六进制甚至是 BigInt 类型:
1 | let binarary = 0b1010_0001_1000_0101 |
使用时必须注意 _ 的两边必须要有类型的数值,否则会报错,以下这些都是无效的写法:
1 | let num = 10_ |